Zgodnie z próbką znajdź funkcję empiryczną. Funkcja dystrybucji empirycznej
Średnia selekcyjna.
Przypuśćmy do badania ogólnego agregatu w stosunku do cechy ilościowej X, pobrano próbkę objętości n.
Medium selektywne nazywane są średnią wartością arytmetyczną znaku zestawu próbki.
![]()
Dyspersja selekcyjna.
W celu obserwowania rozproszenia cechy ilościowej wartości próbek wokół jego średniej wartości wprowadzono charakterystykę podsumowującą - selektywną dyspersję.
Selektywne dyspersja nazywana jest średnie kwadraty arytmetyczne odchylenia obserwowanych wartości funkcji z ich średniej wartości.
Jeśli wszystkie znaki próbki są inne, to

Naprawiono dyspersję.
Dyspersja selektywna jest stronniczym oszacowaniem ogólnej dyspersji, tj. Matematyczne oczekiwanie na selektywnej dyspersji nie jest równe szacowanej ogólnej dyspersji, ale równej
![]()
Aby poprawić dyspersję próbki, wystarczy pomnożyć go przez frakcję
Selektywny współczynnik korelacji.znajduje się według Formuły

gdzie - selektywne średnie odchylenia kwadratowe ilości i.
Selektywny współczynnik korelacji pokazuje linie połączenia liniowego między i: bliżej jednego, tym silniejsze połączenie liniowe między i.
23. Wielokąt częstotliwości nazywany jest linią przerywaną, segmentami, które łączą punkty. Aby skonstruować wielokąt częstotliwości na osi odciętej, warianty są osadzane, a na osi rzędnej - odpowiednie częstotliwości odpowiadające im i łączyć punkty z liniami prostymi.
Względny wielokąt częstotliwości jest zbudowany w taki sam sposób, z wyjątkiem tego, że częstotliwości względne są odroczone na osi rzędnej.
Histogram częstotliwości nazywany jest stopniową liczbą składającą się z prostokątów, których podstawy są częściowe odstępy czasu z długim H, a wysokość jest równa stosunku. Aby skonstruować histogram częstotliwości na osi odcięcia, odstępy częściowe są zdeponowane, a istnieją segmenty, równoległej osi odcięcia na odległość (wysokość). Obszar prostokąta I-T jest - ilość częstotliwości odstępu Wariant I-O, dlatego obszar histogramu częstotliwości jest równy sumie wszystkich częstotliwości, tj. Próbowanie.


Funkcja dystrybucji empirycznej
gdzie n x. - Liczba wartości selektywnych mniejszych x.; n. - Próbkowanie.
22 Przeprowadzaj podstawowe koncepcje statystyk matematycznych
. Podstawowe koncepcje statystyk matematycznych. Ogólny kruszywo i próbka. Seria wariacyjna, rząd statystyczny. Próbka z grilla. Grillowana seria statystyczna. Częstotliwość wielokąta. Selektywna funkcja dystrybucji i histogram.
Ogólny agregat- Dostępne są wszystkie wiele obiektów.
Próba - Zestaw obiektów losowo wybranych z populacji ogólnej.
Nazywana jest sekwencja opcji odnotowanej w kolejności rosnącej wariacyjnyw pobliżu i lista opcji i odpowiednich częstotliwości lub częstotliwości względnych - stick-up: Herbata wybrana z populacji ogólnej.
Wielokątczęstotliwości nazywane są przerywaną linią, których segmenty, które łączą punkty.
Częstotliwość histogramu. Nazywają sekundą figurą składającą się z prostokątów, których podstawy służą jako odstępy częściowe o długości H, a wysokość jest równa stosunku.
Selektywna (empiryczna) funkcja dystrybucji Funkcja wywołania F *(x.) Definiowanie każdej wartości h. Względna częstotliwość zdarzeń. X.< x.
Jeśli zbadano pewne ciągłe znak, seria wariacyjna może składać się z bardzo dużej liczby. W tym przypadku jest wygodniejsze w użyciu próbka z grilla. Aby go uzyskać, przedział, w którym zawierają wszystkie zaobserwowane wartości znaków, podzielone na kilka równych odstępów częściowych h.a następnie znajdź dla każdego częściowego interwału n I. - suma częstotliwości opcji jA.- I interwał.
20. Zgodnie z prawem dużej liczby nie należy rozumieć jako jedno prawo ogólne związane z dużą liczbą. Prawo dużych liczb jest uogólnioną nazwą kilku twierdzeń, z których wynika, że \u200b\u200bz nieograniczonym wzrostem liczby testów, średnie wartości mają tendencję do pewnej stałej.
Należą do nich Twierdzenia Chebyseva i Bernoulliego. Twierdzenie Chebysev jest najczęstszym prawem dużej liczby.
Dowód twierdzeń zjednoczonych do terminu "Prawo dużych liczb" jest nierówność ChebSheva, zgodnie z którą ustalono prawdopodobieństwo odstępstwa od jego oczekiwania matematycznego:
![]()
19 Dystrybucja Pearson (Hee - Square) - Dystrybucja zmiennej losowej
gdzie losowe zmienne. X 1, x 2, ..., x n Niezależny i mają tę samą dystrybucję N.(0,1). Jednocześnie liczba komponentów, tj. n.nazywa się "liczbą stopni wolności" dystrybucji hee - placu.
Dystrybucja chi-kwadratowa jest używana przy ocenie dyspersji (przy użyciu interwału zaufania), gdy sprawdzając hipotezy zgody, jednorodności, niezależności,
Dystrybucja t. Student jest dystrybucją zmiennej losowej
gdzie losowe zmienne. U. i X. niezależny U. ma standardowy rozkład normalny N.(0,1), i X. - Dystrybucja Hee - Plac z N. stopnie swobody. W którym n. Nazywany "liczbą stopni wolności" dystrybucji ucznia.
Jest stosowany przy ocenie oczekiwań matematycznych, wartości prognozy i innych cechach przy użyciu przedziałów ufności, przy sprawdzeniu hipotez na wartościach oczekiwań matematycznych, współczynniki zależności regresji,
Dystrybucja Fishera to losowa zmienna dystrybucja
Dystrybucja Fishera jest używana podczas sprawdzania hipotez na adekwatności modelu w analizie regresji, w sprawie równości dyspersji iw innych zadaniach stosowanych statystyk
18Regresja liniowa Jest to narzędzie statystyczne wykorzystywane do przewidywania przyszłych cen opartych na wcześniejszych danych i zwykle stosuje się w celu ustalenia, gdy ceny są przegrzane. Najmniejsza metoda kwadrata służy do budowy "najbardziej odpowiedniej" linii prostej poprzez serię wartości cen. Punkty cenowe używane jako dane wejściowe mogą być dowolną z następujących wartości: otwarcie, zamykanie, maksimum, minimum,
17. Dwuwymiarowe zmienne losowe nazywane są zamówionym zestawem dwóch zmiennych losowych lub.
Przykład. Dołączane są dwie kostki gry. - liczba punktów spadła odpowiednio na pierwsze i drugie kostki
Uniwersalny sposób na ustalenie prawa rozkładu dwuwymiarowej zmiennej losowej jest funkcja dystrybucji.
15.m.oo dyskretne zmienne losowe
Nieruchomości:
1) M.(DO.) = DO., DO. - stała;
2) M.(Cx.) = Cm.(X.);
3) M.(X 1. + X 2.) = M.(X 1.) + M.(X 2.), gdzie X 1., X 2. - niezależne zmienne losowe;
4) M.(X 1 x 2) = M.(X 1.)M.(X 2.).
Matematyczne oczekiwanie na sumę zmiennych losowych jest równa sumie ich matematycznych oczekiwań, tj.
Matematyczne oczekiwania różnicy zmiennych losowych jest równa różnicy w ich oczekiwań matematycznych, tj.
Matematyczne oczekiwanie na dzieło zmiennych losowych jest równy produktowi ich matematycznych oczekiwań, tj.
Jeśli wszystkie wartości wzroku o wartości losowej (zmniejszenia) do tej samej liczby C, to jego oczekiwania matematyczne wzrośnie (zmniejszenie) tego samego numeru
14. Wykładniczy(wykładniczy) Prawo dystrybucji X. Ma orientacyjny (wykładniczy) prawo dystrybucyjne z parametrem λ\u003e 0, jeśli gęstość prawdopodobieństwa jest:
![]()
Wartość oczekiwana: .
Dyspersja :.
Orientacyjna prawa dystrybucji odgrywa dużą rolę w teorii masowej służby i teorii niezawodności.
13. Prawo normalne charakteryzuje się częstotliwością awarii A (t) lub gęstości prawdopodobieństwa awarii F (t) formularza:
 , (5.36)
, (5.36)
gdzie σ-rms odchylenie x.;
m. x. - oczekiwanie matematyczne SV x.. Ten parametr jest często określany jako środek dyspersji lub najbardziej prawdopodobnej wartości H..
x.- Losowa wartość, dla której czas może zająć czas, wartość bieżąca, wartość napięcia elektryczna i inne argumenty.
Normalne prawo jest prawem dwukarapowym, aby nagrywać, które musisz znać m x. i σ.
Dystrybucja normalna (dystrybucja Gaussa) jest wykorzystywana do oceny wiarygodności produktów, do których wpływa szereg przypadkowych czynników, z których każdy ma nieznacznie wpływa na wynikający efekt
12. Jednolity prawo dystrybucji. Ciągła ilość losowa X. ma jednolite prawo dystrybucji w segmencie [ zA., b.] Jeśli jej gęstość prawdopodobieństwa jest stała w tym segmencie i jest zero na zewnątrz, tj.

Przeznaczenie :.
Wartość oczekiwana: .
Dyspersja :.
Wartość losowa H.Rozproszone przez jednolite prawo w segmencie jest nazywany liczba losowa Od 0 do 1. służy jako materiał źródłowy, aby uzyskać zmienne losowe z dowolnym prawem dystrybucyjnym. Jednolite prawo dystrybucyjne jest stosowane w analizowaniu błędów zaokrąglania podczas obliczeń numerycznych, w wielu masowych zadaniu konserwacji, z modelowaniem statystycznymi obserwacji podporządkowanymi do określonej dystrybucji.
11. Definicja. Gęstość dystrybucji Prawdopodobieństwa ciągłej zmiennej losowej X nazywana jest funkcją f (x) - Pierwsza pochodna funkcji dystrybucji F (x).
Nazywano również gęstość dystrybucji funkcja różnicowa. Aby opisać dyskretną zmienną losową, gęstość rozkładu jest niedopuszczalna.
Znaczeniem gęstości dystrybucji jest to, że pokazuje, jak często pojawia się losowa komórka w niektórych sąsiedztwie punktu h. Przy powtarzaniu eksperymentów.
Po podaniu funkcji gęstości dystrybucji i dystrybucji można podać następującą definicję ciągłej zmiennej losowej.
10. Gęstość prawdopodobieństwa, gęstość dystrybucji prawdopodobieństwa wartości losowej X, jest funkcją p (x) taką 
iz jakimkolwiek< b вероятность события a < x < b равна
.
Jeśli p (x) jest ciągły, a następnie wystarczająco małym prawdopodobieństwem Δx nierówności x< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
i jeśli f (x) odróżnia się, to ![]()
Wykład 13. Koncepcja statystycznych szacunków zmiennych losowych
Niech będzie znany statystyczny rozkład częstotliwości cechy ilościowej X. Oznacz liczbę obserwacji, w których wartość funkcji mniejszą niż X i N jest całkowitą liczbą obserwacji. Oczywiście względna częstotliwość zdarzenia x< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Funkcja dystrybucji empirycznej (Funkcja pobierania próbek) Zadzwoń do funkcji Definiowanie dla każdej wartości x częstotliwość zdarzeń względna X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
W przeciwieństwie do funkcji dystrybucji próbki empirycznej, funkcja dystrybucji ogólnej populacji jest nazywana funkcja dystrybucji teoretycznej.Różnica między tymi funkcjami jest ta funkcja teoretyczna prawdopodobieństwowydarzenia X.< x, тогда как эмпирическая – częstotliwość względnatego samego wydarzenia.
Z wzrostem n względnej częstotliwości zdarzeń x< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Właściwości funkcji dystrybucji empirycznej:
1) Wartości funkcji empirycznej należą do segmentu
2) - Funkcja nie malejącej
3) Jeśli - najmniejszy wariant, a następnie \u003d 0 z, jeśli jest to największy wariant, a następnie \u003d 1 na.
Funkcja dystrybucji próbki empirycznej służy do oszacowania teoretycznej funkcji dystrybucji ogólnej populacji.
Przykład. Konstruując funkcję empiryczną przez pobieranie próbek:
| Opcje | |||
| Częstotliwość |
Znajdź rozmiar próbki: 12 + 18 + 30 \u003d 60. Najmniejszy przykład wykonania wynosi 2, dlatego \u003d 0 w x £ 2. Wartość x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x> 10. W ten sposób żądana funkcja empiryczna ma formularz:
Najważniejsze właściwości szacunków statystycznych
Niech podejmie się pewnego ilościowego znaku ludności ogólnej. Załóżmy, że względy teoretyczne możliwe było zainstalowanie, co dokładnie Dystrybucja ma znak i konieczne jest oszacowanie parametrów, które jest określone. Na przykład, jeśli badana funkcja jest dystrybuowana normalnie w ogólnej populacji, konieczne jest oszacowanie oczekiwań matematycznych i średniego odchylenia kwadratowego; Jeśli znak ma dystrybucję Poissona - konieczne jest oszacowanie parametru L.
Zwykle istnieją tylko dane próbkowane, na przykład, wartości cechy ilościowej uzyskanej w wyniku n niezależnych obserwacji. Biorąc pod uwagę, jak można powiedzieć, że niezależne zmienne losowe znajdź statystyczną ocenę nieznanego parametru dystrybucji teoretycznej - oznacza znalezienie funkcji z obserwowanych zmiennych losowych, co daje przybliżoną wartość szacowanego parametru. Na przykład, aby ocenić matematyczne oczekiwania na temat normalnego rozkładu, funkcja funkcji wykonuje średnią arytmetykę
W celu uzyskania szacunków statystycznych podawania prawidłowych przybliżeń szacowanych parametrów, muszą spełniać pewne wymagania, wśród których najważniejsze wymagania są inwalidztwo i konsystencja szacunki.
Pozwolić - statystyczna ocena nieznanego parametru dystrybucji teoretycznej. Załóżmy, że przez objętość próbki n, znaleziono oszacowanie. Powtarzamy doświadczenie, tj. Wyciąg z ogólnej populacji kolejną próbkę tego samego objętości i zgodnie z jego danymi, otrzymujemy kolejną ocenę. Wielokrotne powtarzanie doświadczeń, otrzymujemy różne liczby. Oszacowanie można uznać za losową ilość, a liczba - jako jego możliwe wartości.
Jeśli ocena daje przybliżoną wartość z nadmiarem. Każda liczba jest bardziej z prawdziwej wartości, w wyniku czego oczekiwanie matematyczne (średnia wartość) zmiennej losowej jest większa niż :. Podobnie, jeśli daje ocenę z wadąnastępnie.
Zatem stosowanie oceny statystycznej, których oczekiwania matematyczne nie jest równe szacowanym parametrem, doprowadziłoby do błędów systematycznych (jeden znak). Jeśli, przeciwnie, gwarantuje z błędów systematycznych.
Rozumiesz Zadzwoń do oceny statystycznej, których matematyczne oczekiwania jest równe szacowanym parametrem z dowolnym wielkością próbki.
Przesiedlony Zadzwoń do oszacowania, który nie spełnia tego warunku.
Oszacowanie oceny nie gwarantuje jeszcze przygotowania dobrego przybliżenia dla szacowanego parametru, ponieważ możliwe wartości mogą być silnie rozproszony wokół średniej, tj. Dyspersja może być znacząca. W tym przypadku ocena znaleziona według jednej próbki, na przykład, może być znacznie usunięta ze średniej wartości, a zatem z najbardziej szacowanego parametru.
Efektywny Zadzwoń do oceny statystycznej, która z danym pobieraniem próbkowania n ma najmniejsza możliwa dyspersja .
Rozważając próbki dużej ilości do szacunków statystycznych, wymaga się wymóg konsystencja .
Zamożny Nazywana jest ocena statystyczna, która dla N® ¥ ma tendencję do prawdopodobnie do szacowanego parametru. Na przykład, jeśli dyspersja niestabilnego oszacowania dla N® ¥ ma tendencję do zera, wówczas taka ocena jest również bogata.
Określenie funkcji dystrybucji empirycznej
Niech $ x $ będzie losową wartością. $ F (x) $ - funkcja dystrybucji tej zmiennej losowej. Zostaniemy przeprowadzimy w tych samych krajach niezależnie od siebie, warunki eksperymentów $ N $ w tej zmiennej losowej. W tym przypadku otrzymujemy sekwencję wartości $ x_1, x_2 $, ..., $ x_n $, która nazywa się próbką.
Definicja 1.
Każda wartość $ X_I $ ($ i \u003d 1,2 $, ..., $ n $) nazywa się opcją.
Jednym z szacunków funkcji dystrybucji teoretycznej jest funkcja dystrybucji empirycznej.
Definicja 3.
Empiryczna funkcja dystrybucji $ F_N (X) nazywana jest funkcją, która określa dla każdej wartości $ X $ względnej częstotliwości $ X
gdzie $ N_X $ jest liczbą wariant mniejszej niż $ x $, $ n $ jest wielkością próbki.
Różnica funkcji empirycznej z teoretycznego polega na tym, że funkcja teoretyczna określa prawdopodobieństwo zdarzenia X
Właściwości funkcji dystrybucji empirycznej
Rozważ teraz kilka podstawowych właściwości funkcji dystrybucji.
Zakres wartości funkcji $ F_N Left (X Prawa) $ - Cut $$.
$ F_n Left (x prawej) $ nie-łamanie funkcji.
$ F_n left (x prawy) $ ciągły po lewej stronie funkcji.
$ F_n left (x prawej) $ fragmentaryzacji stałej funkcji i wzrasta tylko w losowych zmiennych $ x $
Niech $ X_1 będzie najmniejszym, a $ X_N $ jest największą opcją. Następnie $ F_N Left (X Prawa) \u003d 0 $ z $ (x (x x) _1 $ i $ F_N Left (X Prawa) \u003d 1 $ z $ x x_n $.
Przedstawiamy twierdzenie, które wiąże teoretyczne i empiryczne funkcje między sobą.
Twierdzenie 1.
Pozwól $ f_n left (x po prawej) $ - funkcja dystrybucji empirycznej, a $ F Left (X Prawa) $ jest teoretyczną funkcją dystrybucji ogólnej próbki. Następnie wykonuje się równość:
[(Mathop (LIM) _ (n do infty) (| f) _n lewe (x prawy) -f left (x prawo) | \u003d 0)
Przykłady zadań, aby znaleźć funkcję dystrybucji empirycznej
Przykład 1.
Pozwól, aby dystrybucja próbki miała następujące dane zarejestrowane za pomocą tabeli:
Obrazek 1.
Znajdź rozmiar próbki, wykonaj funkcję dystrybucji empirycznej i zbuduj jego harmonogram.
Objętość próbkowania: $ n \u003d 5 + 10 + 15 + 20 \u003d 50 USD.
Według nieruchomości 5, mamy to z $ X $ $ 1 $ F_n Left (X Prawa) \u003d 0 $, z $ X\u003e 4 $ $ F_N Left (X Prawa) \u003d 1 $.
Wartość X.
Wartość X.
Wartość X.
Dostajemy więc:

Rysunek 2.

Rysunek 3.
Przykład 2.
20 miast losowo wybrano z miast centralnej części Rosji, dla których uzyskano następujące dane przy kosztach podróży w transporcie publicznym: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12 , 15, 15, 15, 13, 13, 12, 12, 15, 14, 14.
Utwórz empiryczną cechę dystrybucji tej próbki i zbuduj jego harmonogram.
Piszemy wartości próbkowania w porządku rosnącym i rozważmy częstotliwość każdej wartości. Otrzymujemy następującą tabelę:
Rysunek 4.
Objętość próbkowania: $ n \u003d 20 USD.
Według nieruchomości 5, mamy to za $ x 6 $ $ $ F_n Left (X Prawa) \u003d 0 $, z $ X\u003e 15 $ $ F_N Left (X Prawa) \u003d 1 $.
Wartość X.
Wartość X.
Wartość X.
Dostajemy więc:

Rysunek 5.
Zbuduj wykres dystrybucji empirycznej:

Rysunek 6.
Oryginalność: 92,12 $ $.
Dowiedz się, jaka jest formuła empiryczna. W chemii EF jest najprostszym sposobem na opisanie połączenia - w rzeczywistości jest lista elementów, które tworzą związek na podstawie ich zawartości procentowej. Należy zauważyć, że ta prosta formuła nie opisuje zamówienie Atomy w połączeniu, po prostu wskazuje, które elementy składają się. Na przykład:
- Związek składający się z 40,92% węgla; 4,58% wodoru i 54,5% tlenu będą miały formułę empiryczną C3H3O3 (przykładem, jak znaleźć efekt tego związku będzie rozpatrywane w drugiej części).
Wspieraj termin "procent". "Stopa procentowa" nazywana jest procentem każdego indywidualnego atomu w rozważanym związku. Aby znaleźć formułę złożoną empiryczną, musisz znać składek procentowy połączenia. Jeśli znajdziesz formułę empiryczną jako zadanie domowe, wtedy zostaną podane zainteresowanie.
- Aby znaleźć procent związku chemicznego w laboratorium, poddaje się ona niektórymi eksperymentami fizycznymi, a następnie - analiza ilościowa. Jeśli nie jesteś w laboratorium, nie musisz robić tych eksperymentów.
Należy pamiętać, że będziesz musiał poradzić sobie z atomami Gram. Gram-atom jest pewną ilością substancji, której masa jest równa swojej masie atomowej. Aby znaleźć gram-atom, musisz użyć następującego równania: Odsetek elementu związku dzieli się na masę atomową elementu.
- Załóżmy na przykład, mamy związek zawierający 40,92% węgla. Masa atomowa węgla wynosi 12, więc nasze równanie będzie miało 40,92/12 \u003d 3,41.
Wiedzieć, jak znaleźć stosunek atomowy. Praca ze związkiem, będziesz miał więcej niż jeden Atom Gram. Po znalezieniu wszystkich gramów z twojego połączenia spójrz na nich. Aby znaleźć stosunek atomowy, musisz wybrać najmniejszą wartość obliczoną Gram-Atom. Następnie konieczne będzie podzielenie wszystkich atomów gramów na najmniejszy gram-atom. Na przykład:
- Załóżmy, że pracujesz ze związkiem zawierającym trzy atomy gramów: 1,5; 2 i 2.5. Najmniejsze z tych liczb wynosi 1,5. Dlatego znaleźć stosunek atomów, musisz podzielić wszystkie numery o 1,5 i umieścić relację między nimi : .
- 1,5 / 1,5 \u003d 1. 2/1,5 \u003d 1,33. 2.5 / 1,5 \u003d 1,66. W związku z tym stosunek atomów jest równy 1: 1,33: 1,66 .
Obserwować, jak przetłumaczyć wartości atomów na liczby całkowite. Nagrywając formułę empiryczną, musisz użyć liczb całkowitych. Oznacza to, że nie możesz użyć numerów takich jak 1,33. Po znalezieniu nastawienia atomów musisz przetłumaczyć numery frakcyjne (np. 1,33) do całości (na przykład, 3). Aby to zrobić, musisz znaleźć liczbę całkowitą, mnożącą, która liczba stosunków atomowych, otrzymasz liczby całkowite. Na przykład:
- Spróbuj 2. Pomnóż liczby stosunku atomowego (1, 1,33 i 1.66) przez 2. otrzymasz 2, 2.66 i 3.32. To nie są liczbami całkowitymi, więc 2 nie pasuje.
- Spróbuj 3. Jeśli pomnojesz 1, 1,33 i 1,66 do 3, będziesz miał odpowiednio 3, 4 i 5. W związku z tym stosunek atomowy liczb całkowitych ma formę 3: 4: 5 .
Jak wiadomo, prawo rozkładu zmiennej losowej można ustawić na różne sposoby. Dyskretna losowa kwota może zostać poproszona przy użyciu szeregu dystrybucji lub zintegrowanej funkcji oraz ciągłej losowej ilości - z całkowitą lub zintegrowaną lub różnicą. Rozważ selektywne analogi tych dwóch funkcji.
Niech będzie selektywny zestaw wartości niektórych przypadkowych ilości objętości  a każdy przykład wykonania z tej całości jest umieszczony zgodnie z jego częstotliwością. Niech będzie dalej
a każdy przykład wykonania z tej całości jest umieszczony zgodnie z jego częstotliwością. Niech będzie dalej  - Niektóre ważne numer i
- Niektóre ważne numer i  - liczba wartości selektywnych zmiennej losowej
- liczba wartości selektywnych zmiennej losowej  , mniejszy
, mniejszy  Numer
Numer  jest częstotliwością wartościach wartości obserwowanych w próbce X., mniejszy
jest częstotliwością wartościach wartości obserwowanych w próbce X., mniejszy  ,
te. Częstotliwość zdarzeń
,
te. Częstotliwość zdarzeń 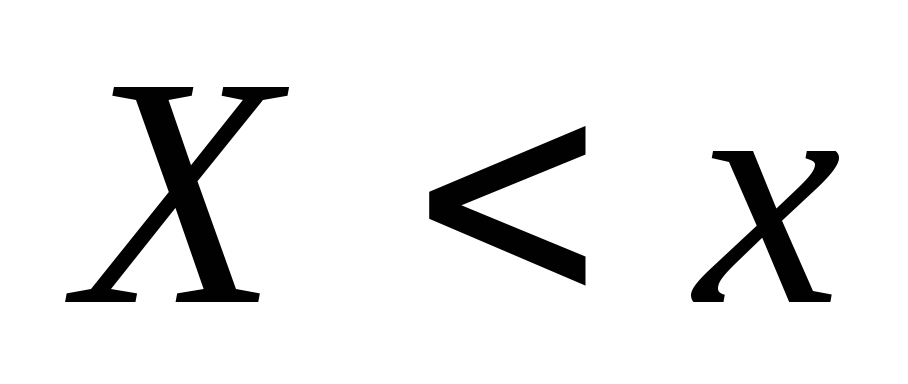 . Kiedy się zmienia x. Ogólnie rzecz biorąc, wartość się zmieni
. Kiedy się zmienia x. Ogólnie rzecz biorąc, wartość się zmieni  . Oznacza to, że częstotliwość względna
. Oznacza to, że częstotliwość względna  jest to funkcja argumentu
jest to funkcja argumentu  . A ponieważ ta funkcja znajduje się zgodnie z selektywnymi danymi uzyskanymi w wyniku eksperymentów, nazywa się on selektywną lub empiryczny.
. A ponieważ ta funkcja znajduje się zgodnie z selektywnymi danymi uzyskanymi w wyniku eksperymentów, nazywa się on selektywną lub empiryczny.
Definicja 10.15. Funkcja dystrybucji empirycznej (Funkcja pobierania próbek) Funkcja połączenia  Definiowanie każdej wartości x. Względna częstotliwość zdarzeń.
Definiowanie każdej wartości x. Względna częstotliwość zdarzeń.  .
.
 (10.19)
(10.19)
W przeciwieństwie do funkcji dystrybucji próbki empirycznej, funkcja dystrybucji FA.(x.) Ogólna populacja zwana funkcja dystrybucji teoretycznej. Różnica między nimi jest ta funkcja teoretyczna FA.(x.)
Określa prawdopodobieństwo wydarzenia  i empiryczna jest względna częstotliwość tego samego wydarzenia. Z twierdzenia Bernoulli następuje
i empiryczna jest względna częstotliwość tego samego wydarzenia. Z twierdzenia Bernoulli następuje
 ,
,
 (10.20)
(10.20)
te. z dużym  prawdopodobieństwo
prawdopodobieństwo  i względna częstotliwość zdarzeń
i względna częstotliwość zdarzeń  .
.  trochę różni się od drugiego. Jest już zgodny z wykonalnością korzystania z funkcji dystrybucji próbki empirycznej dla przybliżonej reprezentacji teoretycznej (integralnej) funkcji dystrybucji ogólnej populacji.
trochę różni się od drugiego. Jest już zgodny z wykonalnością korzystania z funkcji dystrybucji próbki empirycznej dla przybliżonej reprezentacji teoretycznej (integralnej) funkcji dystrybucji ogólnej populacji.
Funkcjonować  i
i  posiadać te same właściwości. Wynika to z definicji funkcji.
posiadać te same właściwości. Wynika to z definicji funkcji. 
Nieruchomości  :
:

Przykład 10.4. Zbuduj funkcję empiryczną na tym dystrybucji próbki:
|
Opcje | |||
|
Częstotliwość |


Decyzja: Znajdź rozmiar próbki n.=
12 + 18 + 30 \u003d 60. Najmniejsza opcja  , W związku z tym,
, W związku z tym,  dla
dla  . Wartość
. Wartość  , mianowicie.
, mianowicie.  obserwowany 12 razy:
obserwowany 12 razy:
 =
= dla
dla  .
.
Wartość x.<
10, mianowicie.  i
i  12 + 18 \u003d 30 razy obserwowano zatem,
12 + 18 \u003d 30 razy obserwowano zatem,  =
=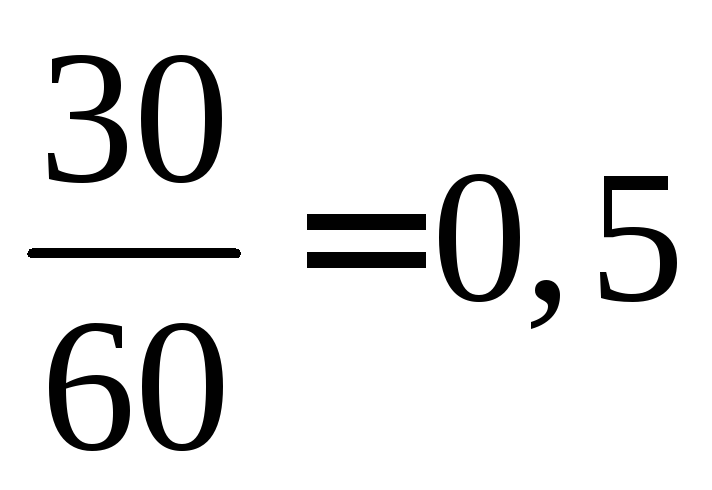 dla
dla  . Dla
. Dla 
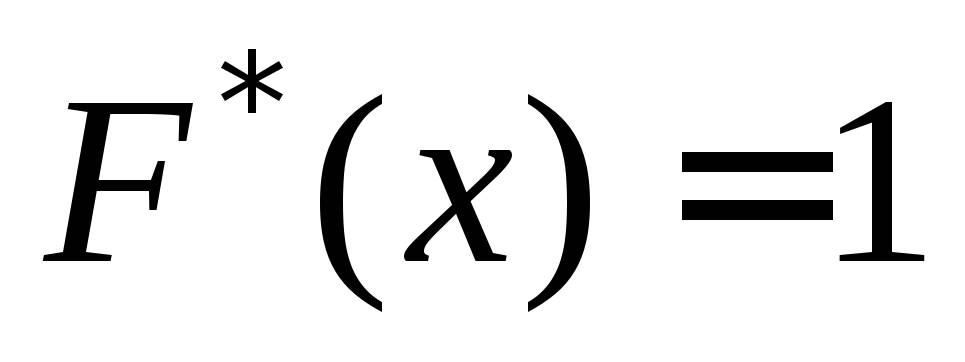 .
.
Pożądana funkcja dystrybucji empirycznej:
 =
=
Harmonogram  przedstawione na rys. 10.2.
przedstawione na rys. 10.2.
R.  ip. 10.2.
ip. 10.2.
Pytania kontrolne.
1. Jakie są główne zadania rozwiązuje statystyki matematyczne? 2. Generalny i selektywny agregat? 3. Podaj definicję próbki. 4. Jakie próbki nazywają się przedstawicielem? 5. Błędy reprezentatywne. 6. Podstawowe sposoby tworzenia próbek. 7. Koncepcje częstotliwości, częstotliwość względna. 8. Koncepcja serii statystycznej. 9. Zapisz formułę stargez. 10. Słowo Koncepcje pobierania próbek, mediów i modów. 11. Częstotliwości wielokąt, histogram. 12. Koncepcja punktu szacunkowego kruszywa selektywnego. 13. Przemieszczony i niewiarygodny punkt szacunkowy. 14. Słowo koncepcja medium selektywnego. 15. Słowo koncepcja selektywnej dyspersji. 16. Słowo Koncepcja selektywnego odchylenia RMS. 17. Słowo koncepcja selektywnego współczynnika zmienności. 18. Słowo koncepcja selektywnej geometrycznej medium.
