ویژگی های توزیع دوتایی. توزیع دو جمله ای
البته، هنگام محاسبه عملکرد توزیع تجمعی، باید توسط Binder و Beta توزیع شده استفاده شود. این روش آگاهانه بهتر از خلاصه فوری زمانی است که n\u003e 10 است.
در کتاب های کلاسیک کتاب های درسی، فرمول ها بر اساس قضیه های محدود (مانند فرمول Moava-laclace) اغلب توصیه می شود برای به دست آوردن مقادیر توزیع دوتایی. لازم به ذکر است که با نقطه نظر صرفا محاسباتی ارزش این قضیه ها نزدیک به صفر است، به ویژه در حال حاضر، زمانی که تقریبا هر جدول یک کامپیوتر قدرتمند است. معایب اصلی تقریب های فوق، دقت کاملا کافی آنها در مقادیر N به طور معمول از اکثر برنامه های کاربردی است. هیچ معایب کمتر، عدم وجود توصیه های واضح در مورد کاربرد یک یا چند تقریبی دیگر (تنها فرمت نامناسب در متون استاندارد داده می شود، آنها با برآوردهای دقت همراه نیستند و بنابراین بسیار مفید نیستند). من می توانم بگویم که هر دو فرمول فقط برای n مناسب هستند< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
من در اینجا وظیفه جستجو برای Quansile را در نظر نمی گیرم: این برای توزیع های گسسته بی اهمیت است و در آن وظایفی که چنین توزیعی بوجود می آیند، معمولا مربوط نیست. اگر کوانتلی هنوز مورد نیاز باشد، توصیه می کنم که کار را برای کار با مقادیر p (مواد مشاهده شده) اصلاح کنید. در اینجا یک مثال است: هنگام اجرای برخی از الگوریتم های فعلی در هر مرحله، لازم است فرضیه آماری در مورد متغیر تصادفی دوتایی را بررسی کنید. با توجه به رویکرد کلاسیک در هر مرحله، لازم است که آمار معیار را محاسبه کنید و ارزش آن را با مرز مجموعه بحرانی مقایسه کنید. از آنجایی که الگوریتم شکسته شده است، لازم است که مرز تعیین شده از مجموعه بحرانی هر بار دیگر (پس از همه، از مرحله به مرحله، حجم نمونه تغییر دهید) لازم است که هزینه های زمان را به طور یکپارچه افزایش ندهد. یک رویکرد مدرن توصیه می کند محاسبه اهمیت مشاهده شده و مقایسه آن با احتمال اعتماد، صرفه جویی در جستجو برای Quansile.
بنابراین، در کدهای زیر، هیچ محاسبه عملکرد معکوس وجود ندارد، در عوض عملکرد Rev_binomialdf نشان داده شده است، که احتمال موفقیت P موفقیت را در یک آزمون جداگانه بر روی مقدار مشخصی از آزمون N، تعداد موفقیت های M در آنها و احتمال را محاسبه می کند از این موفقیت m این از پیوند فوق ذکر شده بین توزیع دوتایی و بتا استفاده می کند.
در واقع، این ویژگی به شما اجازه می دهد تا مرزهای فواصل اعتماد را دریافت کنید. در حقیقت، ما فرض می کنیم که در آزمایش های Binomial N ما موفقیت را دریافت کردیم. همانطور که شناخته شده است، محدودیت چپ فاصله اطمینان دوجانبه برای پارامتر P با سطح اطمینان 0، اگر m \u003d 0، و برای راه حل معادله است  . به طور مشابه، مرز راست 1، اگر m \u003d n، و برای راه حل معادله است
. به طور مشابه، مرز راست 1، اگر m \u003d n، و برای راه حل معادله است  . از اینجا این به این معنی است که برای جستجو برای مرز چپ، ما باید نسبت به معادله را حل کنیم
. از اینجا این به این معنی است که برای جستجو برای مرز چپ، ما باید نسبت به معادله را حل کنیم  ، و برای پیدا کردن حق معادله
، و برای پیدا کردن حق معادله  . آنها در توابع binom_leftci و binom_Rightci حل می شوند که به ترتیب مرزهای بالایی و پایین تر از فاصله اطمینان دو طرفه را به دست می آورند.
. آنها در توابع binom_leftci و binom_Rightci حل می شوند که به ترتیب مرزهای بالایی و پایین تر از فاصله اطمینان دو طرفه را به دست می آورند.
من می خواهم توجه داشته باشم که اگر شما نیاز به دقت کاملا باور نکردنی نداشته باشید، پس با استفاده از تقریبا بزرگ، ممکن است از تقریب زیر استفاده کنید [B.L. ون Der Warden، آمار ریاضی. M: IL، 1960، CH. 2، ثانیه 7]:  جایی که G یک توزیع نرمال کم است. مقدار این تقریب این است که تقریبهای بسیار ساده وجود دارد، به شما این امکان را می دهد که مقدار کمتری از توزیع نرمال را محاسبه کنید (متن را در محاسبه توزیع نرمال و بخش مربوطه این کتاب مرجع ببینید). در عمل من (عمدتا، با n\u003e 100)، این تقریب حدود 3-4 کاراکتر بود که معمولا به اندازه کافی کافی است.
جایی که G یک توزیع نرمال کم است. مقدار این تقریب این است که تقریبهای بسیار ساده وجود دارد، به شما این امکان را می دهد که مقدار کمتری از توزیع نرمال را محاسبه کنید (متن را در محاسبه توزیع نرمال و بخش مربوطه این کتاب مرجع ببینید). در عمل من (عمدتا، با n\u003e 100)، این تقریب حدود 3-4 کاراکتر بود که معمولا به اندازه کافی کافی است.
برای محاسبه با استفاده از کدهای زیر، فایل betadf.h مورد نیاز خواهد بود، betadf.cpp (به بخش توزیع بتا مراجعه کنید)، و همچنین loggamma.h، loggamma.cpp (به ضمیمه A مراجعه کنید). شما همچنین می توانید نمونه ای از استفاده از توابع را ببینید.
فایل binomialdf.h
| # Fifndef __binomial_h__ #include "betadf.h" دو binomialdf (دو آزمایش دوبار، موفقیت دوگانه، دو برابر P)؛ / * * اجازه دهید "آزمایشات" مشاهدات مستقل وجود داشته باشد * با احتمال "P" موفقیت در هر کدام. * احتمال B (موفقیت | محاکمات، P) محاسبه شده است که تعداد * موفقیت بین 0 و "موفقیت" (شامل) نتیجه گیری می شود. * / double rev_binomialdf (آزمایش دوبار، موفقیت های دوگانه، دو y)؛ / * * فرض کنید احتمال این احتمال وجود داشته باشد که حداقل موفقیت M داشته باشد * در آزمون های آزمایشی طرح Bernoulli. این تابع احتمال موفقیت P * را در یک آزمون جداگانه پیدا می کند. * * در محاسبات، نسبت زیر استفاده می شود * * 1 - p \u003d rev_beta (موفقیت های محاکمات | موفقیت + 1، y). * / double binom_leftci (آزمایش دوبار، موفقیت های دوگانه، دو سطح)؛ / * اجازه دهید "آزمایشات" مشاهدات مستقل وجود داشته باشد * با احتمال موفقیت "P" در هر * و تعداد موفقیت "موفقیت" است. * محدودیت سمت چپ فاصله اطمینان دوجانبه * با سطح سطح اهمیت محاسبه می شود. * / double binom_Rightci (دو، دو، موفقیت دوگانه، دو سطح)؛ / * اجازه دهید "آزمایشات" مشاهدات مستقل وجود داشته باشد * با احتمال موفقیت "P" در هر * و تعداد موفقیت "موفقیت" است. * مرز راست از فاصله اطمینان دوجانبه * با سطح اهمیت محاسبه می شود. * / #endif / * به پایان می رسد #ifndef __binomial_h__ * / |
فایل binomialdf.cpp.
| / ***************************************************************************** ********** / / * توزیع دو جمله ای * / / ******************************** *************************** / #عبارتند از. |
تئوری احتمالی در زندگی ما غیرممکن است. ما به آن توجه نمی کنیم، اما هر رویداد در زندگی ما یک احتمال دارد. با توجه به تعداد زیادی از گزینه های توسعه رویدادها، لازم است که به احتمال زیاد و کمترین احتمال آنها تعیین شود. این دقیقا برای تجزیه و تحلیل چنین داده های احتمالی گرافیکی است. در این ما می توانیم به توزیع کمک کنیم. Binomial یکی از ساده ترین و دقیق ترین است.
قبل از ادامه به طور مستقیم به ریاضیات و تئوری احتمالات، بیایید با کسانی که برای اولین بار چنین توزیع شده بودند، مقابله کنیم و تاریخ توسعه دستگاه ریاضی برای این مفهوم چیست.
تاریخ
مفهوم احتمال از زمان های قدیم شناخته شده است. با این حال، ریاضیدانان باستانی اهمیت خاصی برای آن ندارند و توانستند تنها مبانی را برای این نظریه بگذارند، که پس از آن نظریه احتمالی شد. آنها برخی از روش های ترکیبی را ایجاد کردند که به شدت به کسانی کمک کرد که بعدها خود را ایجاد و توسعه دادند.
در نیمه دوم قرن هفدهم، تشکیل مفاهیم اساسی و روش های نظریه احتمالی آغاز شد. متغیرهای تصادفی معرفی شدند، روش هایی برای محاسبه احتمال وقوع رویدادهای مستقل و وابسته پیچیده و وابسته. این علاقه ها به مقادیر تصادفی و احتمالات تصادفی، قمار بود: هر فرد می خواست بداند چه شانس او \u200b\u200bباید در بازی برنده شود.
گام بعدی کاربرد در تئوری احتمال روش های تجزیه و تحلیل ریاضی بود. این در ریاضیدانان برجسته مانند لاپلاس، گاوس، پواسون و برنولی مشغول به کار بود. آنها این بودند که این منطقه ریاضیات را به یک سطح جدید پیشرفت کرد. جیمز برنولی بود که قانون توزیع دوتایی را باز کرد. به هر حال، همانطور که بعدا متوجه شدیم، بر اساس این کشف، چند مورد دیگر، که مجاز به ایجاد قانون توزیع عادی و بسیاری دیگر دیگر بود.
در حال حاضر، قبل از شروع به توصیف توزیع دوتایی، ما کمی طراوت کمی در حافظه مفهوم نظریه احتمالی، احتمالا قبلا از نیمکت مدرسه فراموش شده است.
اصول نظریه احتمالی
ما چنین سیستم هایی را در نظر می گیریم که تنها دو خروجی ممکن است: "موفقیت" و "موفقیت". در مثال آسان است که به راحتی درک کنیم: ما سکه را پرتاب می کنیم، فهمیدن آنچه که عجله می افتد. احتمال هر یک از رویدادهای احتمالی (عجله سقوط خواهد کرد - "موفقیت"، عقاب سقوط خواهد کرد - "موفقیت") برابر با 50 درصد با تعادل ایده آل سکه و عدم وجود عوامل دیگر که ممکن است تاثیر بگذارد آزمایش.
این ساده ترین رویداد بود. اما سیستم های پیچیده ای نیز وجود دارد که در آن اقدامات پی در پی انجام می شود، و احتمال نتایج نتایج این اقدامات متفاوت است. به عنوان مثال، چنین سیستم را در نظر بگیرید: در یک جعبه، محتویاتی که ما نمی توانیم ببینیم، شش توپ کاملا یکسان، سه جفت رنگ آبی، قرمز و سفید قرار می گیرند. ما باید در چند توپ تصادفی دریافت کنیم. بر این اساس، کشیدن یکی از توپ های سفید، ما احتمال را کاهش می دهیم که توپ سفید نیز به ما می آید. این اتفاق می افتد زیرا تعداد اشیاء در سیستم تغییر می کند.
در بخش بعدی، مفاهیم ریاضی پیچیده تر را در نظر می گیریم، دقیقا به آنچه که آنها به معنای کلمات "توزیع نرمال"، "توزیع دوجانبه" و مانند آن است، اعمال می شود.

عناصر آمار ریاضی
در آمار، که یکی از کاربردهای تئوری احتمالی است، نمونه های زیادی وجود دارد زمانی که داده ها برای تجزیه و تحلیل به صراحت نیستند. این است که نه در عددی، بلکه به شکل تقسیم بر ویژگی ها، به عنوان مثال، توسط جنس. به منظور اعمال یک دستگاه ریاضی به چنین اطلاعاتی و نتیجه گیری برخی از نتایج حاصل از نتایج به دست آمده، داده های منبع در فرمت عددی مورد نیاز است. به عنوان یک قاعده، برای اجرای این، یک نتیجه مثبت به مقدار 1 و منفی تعیین می شود. بنابراین، ما داده های آماری را دریافت می کنیم که می توان با استفاده از روش های ریاضی تجزیه و تحلیل کرد.
گام بعدی در درک آنچه توزیع دوتایی یک متغیر تصادفی تعیین کننده پراکندگی متغیر تصادفی و انتظارات ریاضی است. با این قسمت در بخش بعدی صحبت کنید.

ارزش مورد انتظار
در حقیقت، آسان است بدانید که انتظارات ریاضی آسان است. سیستم را در نظر بگیرید که رویدادهای مختلفی با احتمال های مختلف شما وجود دارد. انتظارات ریاضی ارزش برابر با مقدار مقادیر این حوادث (و فرم ریاضی ما در بخش گذشته صحبت کردیم) به احتمال زیاد اجرای آنها نامیده می شود.
انتظار ریاضی توزیع دوقطبی با همان طرح محاسبه می شود: ما ارزش یک متغیر تصادفی را می گیریم، آن را به احتمال زیاد نتیجه مثبت می گیریم، و سپس داده های به دست آمده برای همه ارزش ها را خلاصه می کنیم. این بسیار راحت است که این داده ها را به صورت گرافیکی ارائه دهیم - بهتر است که تفاوت بین انتظارات ریاضی مقادیر مختلف درک شود.
در بخش بعدی، ما کمی درباره مفهوم دیگری - پراکندگی یک متغیر تصادفی به شما خواهیم گفت. همچنین با چنین مفهومی به عنوان یک توزیع احتمالی دوتایی همراه است و مشخصه آن است.

پراکندگی توزیع دوجانبه
این مقدار به شدت مربوط به قبلی است و همچنین توزیع داده های آماری را مشخص می کند. این یک مربع متوسط \u200b\u200bانحراف ارزش ها از انتظارات ریاضی آنها است. به عبارت دیگر، پراکندگی یک متغیر تصادفی، مجموع مربعات تفاوت بین ارزش متغیر تصادفی و انتظارات ریاضی آن است که با احتمال این رویداد ضرب می شود.
به طور کلی، این همه ما باید در مورد پراکندگی بدانیم تا درک کنیم که توزیع دوجانبه احتمالی چیست. حالا بیایید به طور مستقیم به موضوع اصلی ما برویم. یعنی آنچه که برای این در ظاهر یک عبارت نسبتا پیچیده "قانون توزیع دوتایی" قرار دارد.

توزیع دو جمله ای
بیایید شروع کنیم که چرا این توزیع دوجانبه است. از کلمه "بن" می آید. شاید شما درباره Binoma نیوتن شنیدید - چنین فرمول که با آن می توانید مجموع دو عدد A و B را به هر درجه غیر منفی تبدیل کنید.
همانطور که احتمالا قبلا حدس زده اید، فرمول Binoma Newton و فرمول توزیع دوتایی تقریبا همان فرمول است. این تنها یک استثنا است که دوم برای مقادیر خاص اعمال می شود و اولین ابزار ریاضی رایج است که برنامه های کاربردی آن می توانند در عمل متفاوت باشند.
فرمول های توزیع
تابع توزیع دوتایی را می توان به عنوان مجموع اعضای زیر ثبت کرد:
(n / (n - k) k!) * p k * q n-k
در اینجا N تعداد تجربیات تصادفی مستقل، تعداد نتایج موفقیت آمیز، Q - تعداد نتایج ناموفق، K تعداد آزمایش است (ممکن است مقادیر از 0 تا N)،! - تعیین فاکتوریل، چنین عملکردی، ارزش آن برابر با محصول تمام اعداد به آن است (به عنوان مثال، برای شماره 4: 4! \u003d 1 * 2 * 3 * 4 \u003d 24).
علاوه بر این، عملکرد توزیع دوتایی را می توان به عنوان یک تابع بتا ناقص ثبت کرد. با این حال، این یک تعریف پیچیده تر است که تنها در هنگام حل مشکلات پیچیده آماری استفاده می شود.
توزیع دوجانبه، نمونه هایی از آن ما در بالا مورد نظر یکی از ساده ترین انواع توزیع در نظریه احتمال است. همچنین توزیع نرمال نیز وجود دارد که یکی از انواع دوتایی است. این اغلب استفاده می شود، و به سادگی در محاسبات. همچنین توزیع Bernoulli، توزیع پواسون، توزیع شرطی وجود دارد. همه آنها مشخصه های گرافیکی از احتمال یک یا چند فرآیند در شرایط مختلف را مشخص می کنند.
در بخش بعدی، جنبه های مربوط به استفاده از این دستگاه ریاضی را در زندگی واقعی در نظر بگیرید. در نگاه اول، البته، به نظر می رسد که این یک چیز دیگر ریاضی است که، به طور معمول، برنامه های کاربردی را در زندگی واقعی پیدا نمی کند، و به هیچ وجه توسط هر کسی مورد نیاز نیست، به جز ریاضیدانان خود. به هر حال، این چنین نیست. پس از همه، تمام انواع توزیع ها و نمایندگی های گرافیکی آنها به طور انحصاری تحت اهداف عملی ایجاد شد و نه به عنوان عواقب دانشمندان.

کاربرد
البته مهمترین کاربرد توزیع در آمار یافت می شود، زیرا تجزیه و تحلیل جامع مجموعه داده ها وجود دارد. همانطور که تمرین نشان می دهد، بسیاری از آرایه های داده ها در مورد توزیع های مشابه مقادیر قرار دارند: مناطق بحرانی مقادیر بسیار کم و بسیار بالا، به عنوان یک قاعده، حاوی موارد کمتری نسبت به مقادیر متوسط \u200b\u200bاست.
تجزیه و تحلیل آرایه های داده های بزرگ نه تنها در آمار مورد نیاز است. به عنوان مثال، در شیمی فیزیکی ضروری است. در این علم، برای تعیین ارزش های بسیاری که با نوسانات تصادفی و حرکات اتم ها و مولکول ها مرتبط هستند، استفاده می شود.
در بخش بعدی، ما با اهمیت استفاده از چنین مفاهیم آماری به عنوان دوتایی برخورد خواهیم کرد توزیع یک متغیر تصادفی در زندگی روزمره برای ما با شما.

چرا به آن نیاز دارم؟
بسیاری از خودشان را در مورد ریاضیات می پرسند. و به هر حال، ریاضیات بیهوده به نام ملکه علم نیست. این مبنای فیزیک، شیمی، زیست شناسی، اقتصاد است و در هر یک از این علوم از جمله هر توزیع استفاده می شود: این که آیا توزیع دوجانبه گسسته یا طبیعی نیست. و اگر ما به جهان در سراسر جهان بهتر شویم، خواهیم دید که ریاضیات در همه جا اعمال می شود: در زندگی روزمره، در محل کار، و حتی روابط انسانی را می توان به صورت داده های آماری ارائه کرد و تجزیه و تحلیل آنها را تجزیه و تحلیل کرد (بنابراین، توسط راه، آنها کسانی را که در سازمان های ویژه درگیر در جمع آوری اطلاعات کار می کنند) انجام می دهند.
در حال حاضر بیایید کمی درباره آنچه که باید انجام دهیم صحبت کنیم، اگر شما نیاز به دانستن این موضوع بسیار بیشتر از آنچه که ما در این مقاله مشخص کرده ایم.
این اطلاعاتی که ما در این مقاله به آن دادیم، دور از کامل است. تفاوت های زیادی در مورد اینکه چه فرم می تواند توزیع شود وجود دارد. توزیع دوجانبه، همانطور که قبلا متوجه شدیم، یکی از گونه های اصلی است که تمام آمار ریاضی و نظریه احتمالی مبتنی بر آن است.
اگر برای شما جالب بود، یا در ارتباط با کار خود، شما باید در این موضوع خیلی بیشتر بدانید، شما باید ادبیات تخصصی را کشف کنید. شروع به دنبال از دوره دانشگاه تجزیه و تحلیل ریاضی و سفر به بخش تئوری احتمال. آگاهی از ردیف ها نیز مفید خواهد بود، زیرا توزیع دوقطبی احتمالات بیش از یک سری از اعضای متوالی نیست.
نتیجه
قبل از تکمیل مقاله، ما می خواهیم چیز دیگری را جالب کنیم. این موضوع مربوط به موضوعات مقاله ما و کل ریاضیات به طور کلی است.
بسیاری از مردم می گویند که ریاضیات علم بی فایده است و هیچ چیز از آنچه در مدرسه رخ داده است، آنها مفید نبودند. اما دانش هرگز اضافی نیست، و اگر چیزی در زندگی شما مفید نیست، به این معنی است که شما فقط این را به یاد نمی آورید. اگر دانش دارید، آنها می توانند به شما کمک کنند، اما اگر آنها نباشند، نمی توانید از آنها برای کمک به آنها صبر کنید.
بنابراین، ما مفهوم توزیع دوتایی و تمام تعاریف مربوطه را در نظر گرفتیم و در مورد چگونگی آن با زندگی ما با شما صحبت کردیم.
پیاده سازی طرح Bernoulli را در نظر بگیرید، I.E. یک سری از آزمون های مستقل تکراری در دسترس است، در هر کدام از این موارد A دارای احتمال مشابهی است که به شماره تست بستگی ندارد. و برای هر آزمون تنها دو خروجی وجود دارد:
1) رویداد A - موفقیت؛
2) رویداد - شکست
با احتمالات ثابت
ما یک مقدار تصادفی گسسته x را معرفی می کنیم - "تعداد رویدادها و پ تست "و پیدا کردن قانون توزیع این متغیر تصادفی. x می تواند مقادیر را ایجاد کند
احتمال ![]() که متغیر تصادفی ارزش را می گیرد x k. واقع شده توسط Bernoulli فرمول
که متغیر تصادفی ارزش را می گیرد x k. واقع شده توسط Bernoulli فرمول
قانون توزیع متغیر تصادفی گسسته تعیین شده توسط فرمول Bernoulli (1) نامیده می شود قانون توزیع دوتایی دائمی پ و r (q \u003d 1-P)شامل فرمول (1) نامیده می شود پارامترهای توزیع دوتایی.
نام "توزیع دوجانبه" با این واقعیت مرتبط است که سمت راست برابری (1) یک عضو عمومی تجزیه باینوم نیوتن است، I.E.
(2)
و از p + q \u003d 1، سمت راست برابری (2) برابر با 1 است
این به آن معناست که
 (4)
(4)
در برابری (3)، عضو اول سعید بخش راست به معنی احتمال این است که در پ تست رویداد و هرگز به نظر نمی رسد، عضو دوم ![]() احتمال وقوع رویداد A یک بار ظاهر می شود، سومین دیک احتمال دارد که رویداد A دو بار ظاهر شود و در نهایت، آخرین عضو p P. - احتمال این که رویداد A دقیقا ظاهر می شود پ زمان.
احتمال وقوع رویداد A یک بار ظاهر می شود، سومین دیک احتمال دارد که رویداد A دو بار ظاهر شود و در نهایت، آخرین عضو p P. - احتمال این که رویداد A دقیقا ظاهر می شود پ زمان.
قانون توزیع دوتایی متغیر تصادفی گسسته به عنوان یک جدول نشان داده شده است:
| H. | 0 | 1 | … | k. | … | n. |
| r | سعید | … | … | p P. |
ویژگی های اصلی عددی توزیع دوتایی:
1) انتظارات ریاضی ![]() (5)
(5)
2) پراکندگی ![]() (6)
(6)
3) انحراف دوم درجه دوم ![]() (7)
(7)
4) مناسب ترین تعداد رویدادها k 0 - این شماره با مشخص شده است پ مربوط به احتمال حداکثر دوتایی است
برای مشخص شده پ و r این تعداد توسط نابرابری تعیین می شود
![]() (8)
(8)
اگر تعداد باشد pR + R. بعد از آن عدد صحیح نیست k 0 به همان اندازه یک بخش کامل از این شماره، اگر pR + R. - عدد صحیح، سپس k 0 این دو معنی دارد
قانون دوقطبی توزیع احتمالی در تئوری تیراندازی، تئوری و عمل کنترل آماری کیفیت محصول، در نظریه خدمات جرم، در نظریه قابلیت اطمینان و غیره اعمال می شود. این قانون را می توان در همه موارد اعمال کرد، زمانی که یک توالی از آزمون های مستقل وجود دارد.
مثال 1:تست کیفیت ثابت شده است که از هر 100 دستگاه نقص 90 قطعه را به طور متوسط \u200b\u200bندارد. یک قانون دوقطبی از توزیع احتمالی تعداد دستگاه های با کیفیت بالا را به صورت تصادفی 4 به دست آورید.
تصمیم گیری:رویداد A - ظاهر آن توسط این بررسی شده است - "به دست آمده در کیفیت دستگاه تصادفی". تحت شرایط مشکل، پارامترهای اصلی توزیع دوتایی:
مقدار تصادفی X تعداد دستگاه های با کیفیت بالا ساخته شده از 4 است که به این معنی است که مقادیر X-Serry احتمال ابتلا به x را با فرمول (1) انجام می دهند:

بنابراین، ارزش توزیع مقدار X، تعداد ابزار با کیفیت بالا ساخته شده از 4 است:
| H. | 0 | 1 | 2 | 3 | 4 |
| r | 0,0001 | 0,0036 | 0,0486 | 0,2916 | 0,6561 |
برای بررسی صحت ساخت توزیع، بررسی کنید که چرا مجموع احتمالات برابر است
پاسخ:قانون توزیع
| H. | 0 | 1 | 2 | 3 | 4 |
| r | 0,0001 | 0,0036 | 0,0486 | 0,2916 | 0,6561 |
مثال 2:روش درمان مورد استفاده منجر به بهبود در 95٪ موارد می شود. پنج بیمار این روش را اعمال کردند. بیشترین ویژگی های عددی متغیر تصادفی X را پیدا کنید - تعداد بازیافت شده از 5 بیمار از این روش استفاده می شود.
توزیع دوتایی را در نظر بگیرید، ما انتظارات ریاضی خود را، پراکندگی، مد را محاسبه می کنیم. با استفاده از تابع MS Excel Binomesp ()، ما نمودار های تابع توزیع و تراکم احتمالات را ساختیم. ما پارامتر توزیع P، انتظارات ریاضی توزیع و انحراف استاندارد را ارزیابی خواهیم کرد. ما همچنین توزیع Bernoulli را در نظر خواهیم گرفت.
تعریف . اجازه دهید آنها برگزار شوند n. تست ها، در هر کدام از آنها تنها 2 رویداد ممکن است رخ دهد: رویداد "موفقیت" با احتمال پ. یا رویداد "شکست" با احتمال Q. \u003d 1-P (به اصطلاح طرح Bernoulli برنولی آزمایش های.).
احتمال به دست آوردن دقیقا ایکس. موفقیت در این n. تست ها برابر هستند:
تعداد موفقیت در نمونه ایکس. یک مقدار تصادفی است که دارای آن است توزیع دو جمله ای (مهندس دوجنی توزیع) پ. و n. – پارامترهای این توزیع هستند.
به یاد بیاورید که برای استفاده طرح های برنولی و به همین ترتیب توزیع دو جمله ای شرایط زیر باید تکمیل شود:
- هر آزمون باید دقیقا دو نتیجه داشته باشد، به شرطی که به عنوان "موفقیت" و "شکست" نامیده می شود.
- نتیجه هر آزمون نباید به نتایج آزمایش های قبلی بستگی داشته باشد (استقلال تست).
- احتمال موفقیت پ. باید برای تمام آزمایشات ثابت باشد.
توزیع دوجانبه در MS اکسل
در MS Excel، از سال 2010، برای یک تابع Binom ()، نام انگلیسی - binom.dist () وجود دارد که به شما امکان می دهد احتمال آن را محاسبه کنید که در نمونه صاف باشد H. "موفقیت" (به عنوان مثال عملکرد تراکم احتمالی p (x)، فرمول بالا را ببینید)، و تابع توزیع انتگرال (احتمال این که در نمونه باشد ایکس. یا کمتر "موفقیت"، از جمله 0).
قبل از MS Excel 2010، اکسل دارای یک تابع binoMap () بود، که همچنین به ما اجازه می دهد که محاسبه کنیم تابع توزیع و چگالی احتمالی p (x). Binomap () در MS Excel 2010 برای سازگاری باقی مانده است.
فایل مثال مثال نمودارها را نشان می دهد توزیع احتمال و .

توزیع دو جمله ای نشانه گذاری شده است ب ( n. ; پ.) .
توجه داشته باشید : برای ساخت تابع توزیع انتگرال نمودار مناسب ایده آل برنامه برای توزیع توزیع – هیستوگرام با گروه بندی . اطلاعات بیشتر در مورد نمودارهای ساختمان را بخوانید مقاله اصلی نمودارها را مطالعه کنید.
توجه داشته باشید : برای سهولت نوشتن، فرمول ها در مثال فایل نام برای پارامترها ایجاد شده است توزیع دو جمله ای : n و p

فایل مثال، محاسبات احتمالی مختلف را با استفاده از توابع MS Excel ارائه می دهد:
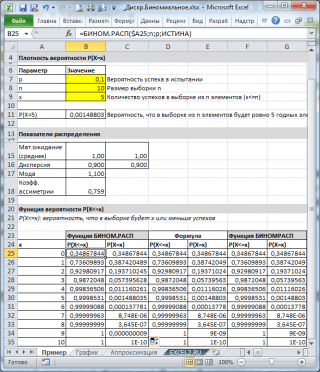
همانطور که در تصویر بالا دیده می شود، فرض می شود که:
- در یک مجموعه بی نهایت، که از آن نمونه ساخته شده است، شامل 10٪ (یا 0.1) عناصر مناسب (پارامتر پ. ، استدلال سوم تابع \u003d bin.rasp ())
- برای محاسبه احتمال این که در نمونه 10 عنصر (پارامتر n. استدلال تابع دوم) دقیقا 5 عناصر مناسب (اول استدلال)، شما باید فرمول را ضبط کنید: \u003d binomasp (5؛ 10؛ 0،1؛ دروغ)
- آخرین، عنصر چهارم، set \u003d false، I.E. ارزش تابع را باز می گرداند توزیع توزیع .
اگر مقدار استدلال چهارم \u003d حقیقت، پس از آن عملکرد BIN () ارزش را باز می گرداند تابع توزیع انتگرال یا به سادگی تابع توزیع . در این مورد، ممکن است این احتمال را محاسبه کنید که در نمونه تعداد عناصر مناسب از محدوده خاصی باشد، به عنوان مثال، 2 یا کمتر (از جمله 0).
برای انجام این کار، شما باید فرمول را بنویسید: \u003d binom.rp (2؛ 10؛ 0.1؛ حقیقت)
توجه داشته باشید : با مقدار X Nenet X ،. به عنوان مثال، فرمول های زیر همان مقدار را به دست می آورند: \u003d بن 2 ؛ 10؛ 0.1؛ درست است، واقعی) \u003d بن 2,9 ؛ 10؛ 0.1؛ درست است، واقعی)
توجه داشته باشید : در فایل مثال چگالی احتمالی و تابع توزیع همچنین با استفاده از تعریف و عملکرد Numcomb () محاسبه شده است.
شاخص های توزیع
که در مثال فایل بر روی ورق فرمول ها برای محاسبه برخی از شاخص های توزیع وجود دارد:
- \u003d n * p؛
- (مربع انحراف استاندارد) \u003d n * p * (1-P)؛
- \u003d (n + 1) * p؛
- \u003d (1-2 * p) * ریشه (n * p * (1-p)).
فرمول را بردارید انتظارات ریاضی توزیع دو جمله ای استفاده كردن طرح Bernoulli .
با تعریف، مقدار تصادفی x در طرح Bernoulli (متغیر تصادفی Bernoulli) تابع توزیع :

این توزیع نامیده می شود توزیع برنولی .
توجه داشته باشید : توزیع برنولی - مورد خصوصی توزیع دو جمله ای با پارامتر n \u003d 1.
اجازه دهید ما 3 آرایه از 100 عدد را با احتمال های مختلف موفقیت تولید کنیم: 0.1؛ 0.5 و 0.9. برای انجام این کار در پنجره نسل اعداد تصادفی پارامترهای زیر را برای هر احتمال p:

توجه داشته باشید : اگر گزینه را تنظیم کنید پراکندگی تصادفی ( بذر تصادفی) شما می توانید یک مجموعه تصادفی خاص از اعداد تولید شده را انتخاب کنید. به عنوان مثال، با تنظیم این گزینه \u003d 25، می توان آن را بر روی رایانه های مختلف تولید کرد همان مجموعه ای از اعداد تصادفی (مگر اینکه، البته، پارامترهای دیگر توزیع هماهنگ شده). مقدار گزینه می تواند کل ارزش را از 1 تا 32 767 انجام دهد. نام گزینه پراکندگی تصادفی می تواند گیج شود بهتر است ترجمه آن را مانند شماره را با اعداد تصادفی تنظیم کنید .
به عنوان یک نتیجه، ما 3 ستون از 100 عدد داریم، به عنوان مثال، شما می توانید احتمال موفقیت را ارزیابی کنید. پ. با توجه به فرمول: تعداد موفقیت / 100 (سانتی متر. مثال فایل به صورت طبیعی).
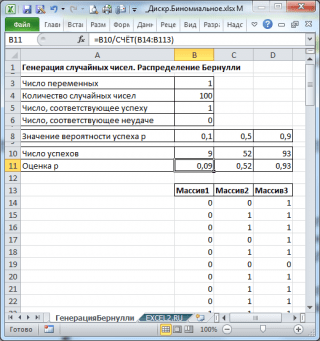
توجه داشته باشید : برای توزیع برنولی با p \u003d 0.5، شما می توانید از فرمول \u003d جیره بندی (0؛ 1)، که مربوط است استفاده کنید.
نسل اعداد تصادفی توزیع دو جمله ای
فرض کنید 7 محصول معیوب در نمونه کشف شده است. این به این معنی است که وضعیت "به احتمال زیاد" است که سهم محصولات معیوب تغییر کرده است پ. که مشخصه فرایند تولید ما است. اگر چه این وضعیت "به احتمال زیاد" است، اما شانس (خطر آلفا، خطا از نوع اول، "هشدار دروغین") وجود دارد، که هنوز هم هست پ. آن را بدون تغییر باقی ماند، و افزایش تعداد محصولات معیوب به دلیل تصادفی نمونه گیری است.
همانطور که در شکل زیر دیده می شود، 7 تعداد محصولات معیوب است که برای فرایند با P \u003d 0.21 با همان مقدار مجاز است آلفای . این به عنوان یک تصویر عمل می کند که زمانی که مقدار آستانه محصولات معیوب در نمونه بیش از حد است، پ. "به احتمال زیاد" افزایش یافته است. عبارت "به احتمال زیاد" به این معنی است که تنها احتمال 10٪ (100٪ -90٪) وجود دارد که انحراف از سهم محصولات معیوب بالای آستانه تنها ناشی از علل است.

بنابراین، بیش از تعداد آستانه محصولات معیوب در نمونه می تواند یک سیگنال باشد که فرآیند ناراحت کننده است و شروع به تولید ب در باره درصد محصولات معیوب را صرف کرد.
توجه داشته باشید : قبل از MS Excel 2010 در اکسل یک تابع CRTBIN () وجود داشت ()، که معادل آن با Binomes () بود. Cretebin () در MS Excel 2010 و بالاتر برای سازگاری قرار دارد.
ارتباط توزیع دوجانبه با سایر توزیعها
اگر پارامتر باشد n. توزیع دو جمله ای تمایل به بی نهایت، و پ. به 0، سپس در این مورد توزیع دو جمله ای این می تواند تقریبی باشد. شرایط را می توان فرموله کرد زمانی که تقریب توزیع پواسون خوب کار می کند:
- پ. (کمتر پ. و بیشتر n. ، نزدیکترین تقریبی)؛
- پ. >0,9 (با توجه به این Q. =1- پ. ، محاسبات در این مورد باید انجام شود Q. (ولی H. نیاز به جایگزینی n. - ایکس.) از این رو Q. و بیشتر n. ، تقریبی دقیق تر است).
در 0.110 توزیع دو جمله ای شما می توانید تقریبی
به نوبه خود، توزیع دو جمله ای می تواند به عنوان یک تقریب خوب زمانی که اندازه کل n باشد توزیع Hypergeometry نمونه برداری نمونه گیری بسیار بیشتر (IE، n \u003e\u003e N یا N / N / N. بیشتر در مورد اتصال توزیع های بالا، شما می توانید در مقاله بخوانید. همچنین نمونه هایی از تقریب ها وجود دارد، و شرایط توضیح داده می شود زمانی که ممکن است با چه چیزی امکان پذیر است دقت.
شورا : در دیگر توزیع های MS اکسل در مقاله یافت می شود.
فصل 7
قوانین خاص توزیع متغیرهای تصادفی
انواع قوانین توزیع متغیرهای تصادفی گسسته
اجازه دهید مقدار تصادفی گسسته بتواند مقادیر را داشته باشد h. 1 , h. 2 , …, x n..... به عنوان مثال، احتمال این مقادیر را می توان با توجه به فرمول های مختلف محاسبه کرد، به عنوان مثال، با استفاده از قضیه های اساسی نظریه احتمالی، فرمول های برنولی یا بعضی از فرمول های دیگر. برای برخی از این فرمول ها، قانون توزیع نام خود را دارد.
شایع ترین قوانین توزیع واریانس تصادفی گسسته، دوتایی، هندسی، هیپرگو سنجی، قانون توزیع پواسون است.
قانون توزیع دوتایی
اجازه دهید آن را تولید کنیم n. تست های مستقل، در هر یک از آنها ممکن است ظاهر شود یا به نظر نمی رسد ولی. احتمال این رویداد در هر آزمون تک ثابت است، به تعداد آزمون بستگی ندارد r=r(ولی) از این رو احتمال هیچ رویدادی وجود ندارد ولی در هر آزمون نیز ثابت و برابر است q.=1–r. مقدار تصادفی را در نظر بگیرید H. برابر با تعداد رویدادها ولی که در n. تست ها بدیهی است، ارزش های این مقدار برابر است
h. 1 \u003d 0 - رویداد ولی که در n. تست ها ظاهر نشد
h. 2 \u003d 1 - رویداد ولی که در n. تست ها یک بار ظاهر شدند؛
h. 3 \u003d 2 - رویداد ولی که در n. تست ها دو بار ظاهر شدند
…………………………………………………………..
x n. +1 = n. - رویداد ولی که در n. تست ها ظاهر شدند n. زمان.
احتمالات این مقادیر را می توان با فرمول برنولی محاسبه کرد (4.1):
جایی که به=0, 1, 2, …, n. .
قانون توزیع دوتایی H.برابر با تعداد موفقیت در n. آزمایش های برنولی، با احتمال موفقیت r.
بنابراین، مقدار تصادفی گسسته دارای توزیع دوتایی (یا با توجه به قانون دوتایی توزیع شده است) اگر مقادیر احتمالی آن 0، 1، 2، ... n.، و احتمالات مربوطه با فرمول (7.1) محاسبه می شود.
توزیع دوجانبه بستگی به دو دارد مولفه های r و n..
تعدادی توزیع یک متغیر تصادفی، با توجه به قانون دوتایی توزیع شده، فرم را تشکیل می دهد:
| H. | … | k. | … | n. | ||
| r | | … | … | |
مثال 7.1 . سه عکس مستقل هدف وجود دارد. احتمال ورود هر ضربه 0.4 است. مقدار تصادفی H. - تعداد بازدید در هدف. تعدادی از توزیع را بسازید.
تصمیم گیری مقادیر ممکن متغیر تصادفی H. هستند h. 1 =0; h. 2 =1; h. 3 =2; h. 4 \u003d 3 ما احتمال های مربوطه را با استفاده از فرمول Bernoulli پیدا می کنیم. نشان می دهد که استفاده از این فرمول در اینجا کاملا توجیه شده است. توجه داشته باشید که احتمال ورود به هدف در یک شات 1-0.4 \u003d 0.6 خواهد بود. دريافت كردن

تعدادی از توزیع به شرح زیر است:
| H. | ||||
| r | 0,216 | 0,432 | 0,288 | 0,064 |
آسان است که تأیید کنید که مجموع تمام احتمالات برابر با 1. تعداد تصادفی خود است H. توزیع شده توسط قانون دوجانبه. ■.
ما انتظارات ریاضی و پراکندگی یک متغیر تصادفی توزیع شده با توجه به قانون دوتایی را پیدا می کنیم.
در صورت حل مثال مثال 6.5 نشان داده شد که انتظارات ریاضی تعداد حضور رویدادها ولی که در n. آزمون های مستقل اگر احتمال ظهور ولی در هر آزمون ثابت و برابر است rخوب n.· r
در این مثال، یک متغیر تصادفی، با توجه به قانون دوتایی توزیع شده است. بنابراین، راه حل نمونه 6.5 اساسا اثبات قضیه زیر است.
تئوری 7.1. انتظار ریاضی متغیر تصادفی گسسته توزیع شده با توجه به قانون دوتایی برابر با محصول تعداد آزمایشات در مورد احتمال "موفقیت"، I.E. M.(H.)= n.· r.
قضیه 7.2.پراکندگی متغیر تصادفی گسسته، با توجه به قانون دوتایی توزیع شده، برابر با محصول تعداد تست ها در مورد احتمال موفقیت "و به احتمال زیاد" شکست "، I.E. D.(H.)= npq
عدم تقارن و بیش از یک متغیر تصادفی، توزیع شده با توجه به قانون دوتایی، توسط فرمول ها تعیین می شود
این فرمول ها را می توان با استفاده از مفهوم لحظات اولیه و مرکزی به دست آورد.
قانون توزیع دوطرفه بسیاری از شرایط واقعی را تحت تأثیر قرار می دهد. برای مقادیر بزرگ n. توزیع دوتایی را می توان با توزیع های دیگر، به ویژه با کمک توزیع پواسون تقریب کرد.
توزیع پواسون
اجازه دهید آن را n.تست های برنولی، با تعداد آزمایشات n. به اندازه کافی عالی قبلا نشان داده شده است که در این مورد (اگر احتمال بیشتری داشته باشد r مناسبت ها ولی بسیار کوچک) برای پیدا کردن احتمال این رویداد ولی ظاهر شدن t. هنگامی که در آزمایشات می توانید از فرمول پواسون استفاده کنید (4.9). اگر مقدار تصادفی H. به معنی تعداد رویدادها است ولی که در n.تست برنولی، احتمال این است H. گرفتن ارزش k. می تواند توسط فرمول محاسبه شود
 , (7.2)
, (7.2)
جایی که λ = nr.
قانون توزیع پواسونتوزیع متغیر تصادفی گسسته نامیده می شود H.که مقادیر احتمالی تعداد کل غیر منفی و احتمالات هستند r t. این مقادیر توسط فرمول (7.2) یافت می شود.
مقدار λ = nrبه نام پارامترتوزیع پواسون
یک متغیر تصادفی توزیع شده توسط قانون پواسون می تواند مجموعه ای بی نهایت از مقادیر را بگیرد. همانطور که برای این احتمال توزیع r ظاهر این رویداد در هر آزمون کوچک است، این توزیع گاهی اوقات قانون پدیده های نادر نامیده می شود.
تعدادی توزیع یک متغیر تصادفی توزیع شده توسط قانون پواسون فرم دارد
| H. | … | t. | … | ||||
| r | … | … |
دشوار نیست اطمینان حاصل کنید که مقدار احتمال رشته دوم 1. برای انجام این کار ضروری است، لازم است به یاد داشته باشید که این تابع را می توان به یک ردیف از Macrolore تقسیم کرد، که برای هر کدام همگام است h.. در این مورد ما داریم
 . (7.3)
. (7.3)
همانطور که اشاره شد، قانون پواسون در موارد محدود محدود، قانون دوجانبه را جایگزین می کند. به عنوان مثال، شما می توانید مقدار تصادفی را به ارمغان بیاورد H.، مقادیر آن برابر با تعداد شکست ها برای یک دوره زمانی خاص با استفاده مکرر از دستگاه فنی است. فرض بر این است که این یک دستگاه قابلیت اطمینان بالا است، I.E. احتمال شکست در یک برنامه بسیار کوچک است.
علاوه بر این حاشیه ها، در عمل، متغیرهای تصادفی توزیع شده تحت قانون پواسون است که مربوط به توزیع دوتایی نیست. به عنوان مثال، توزیع پواسون اغلب زمانی استفاده می شود که آنها با تعداد رویدادهایی که در زمان زمان ظاهر می شوند (تعداد تماس ها به تبادل تلفن در عرض یک ساعت، تعداد ماشین ها در روز شستشو خودرو وارد شده اند، تعداد توقف ماشین های در هفته، و غیره.). تمام این حوادث باید شکل بگیرند، به اصطلاح جریان حوادث، که یکی از مفاهیم اساسی نظریه نگهداری جمعی است. پارامتر λ به طور متوسط \u200b\u200bشدت جریان وقایع را مشخص می کند.
مثال 7.2 . دانشکده دارای 500 دانشجو است. این احتمال وجود دارد که 1 سپتامبر روز تولد برای سه دانش آموز این دانشکده تولد است؟
تصمیم . از آنجا که تعداد دانش آموزان n.\u003d 500 به اندازه کافی بزرگ است r - احتمال اول سپتامبر به هر یک از دانش آموزان برابر است، به عنوان مثال به اندازه کافی کوچک، پس ما می توانیم فرض کنیم که مقدار تصادفی H. - تعداد دانشجویان متولد اول سپتامبر تحت قانون پواسون با پارامتر توزیع می شود λ = np\u003d \u003d 1.36986. سپس، توسط فرمول (7.2) ما دریافت می کنیم
قضیه 7.3.مقدار تصادفی را بگذارید H. توزیع شده توسط قانون پواسون. سپس انتظارات ریاضی و پراکندگی آن برابر با یکدیگر و برابر با ارزش پارامتر است λ . M.(ایکس.) = D.(ایکس.) = λ = np.
شواهد و مدارک. با تعیین انتظارات ریاضی، با استفاده از فرمول (7.3) و تعدادی توزیع یک متغیر تصادفی توزیع شده توسط قانون پواسون، ما به دست می آوریم
قبل از پیدا کردن پراکندگی، ما انتظارات ریاضی مربع متغیر تصادفی را در نظر می گیریم. دريافت كردن

از اینجا، با تعریف پراکندگی، ما دریافت می کنیم
قضیه ثابت شده است.
با استفاده از مفاهیم لحظات اولیه و مرکزی، می توان نشان داد که برای یک متغیر تصادفی، تحت قانون پواسون توزیع شده است، ضرایب عدم تقارن و اضطراب توسط فرمول ها تعیین می شود
درک آن دشوار نیست، زیرا در محتوای معنایی پارامتر λ = np مثبت است، سپس نامتقارن و اموال همواره نامتقارن مثبت و تبادل نظر در یک متغیر تصادفی هستند.
