Pronađite empirijsku funkciju prema podacima uzorka. Empirijska funkcija raspodjele
Prosjek uzorka.
Neka se izvuče uzorak volumena n za proučavanje opće populacije s obzirom na kvantitativni atribut X.
Srednja vrijednost uzorka naziva se aritmetička sredina atributa populacije uzorka.
![]()
Varijansa uzorka.
Kako bi se promatrala disperzija kvantitativne karakteristike vrijednosti uzorka oko njene srednje vrijednosti, uvodi se zbirna karakteristika - varijansa uzorka.
Varijansa uzorka je aritmetička sredina kvadrata odstupanja promatranih vrijednosti obilježja od njihove srednje vrijednosti.
Ako su sve vrijednosti karakteristike odabira različite, tada

Ispravljena varijansa.
Varijansa uzorka je pristrana procjena opće varijance, tj. matematičko očekivanje varijance uzorka nije jednako procijenjenoj općoj varijansi, ali je
![]()
Za ispravljanje varijance uzorka dovoljno ju je pomnožiti s razlomom
Koeficijent selektivne korelacije se nalazi po formuli

gdje su uzorci standardne devijacije vrijednosti i.
Koeficijent korelacije uzorka pokazuje bliskost linearnog odnosa između i: što je bliži jedan, to je jači linearni odnos između i.
23. Poligon frekvencija je polilinija čiji segmenti povezuju točke. Za izgradnju poligona frekvencija opcije su položene na os apscise, a frekvencije koje im odgovaraju položene su na os ordinate, a točke su povezane segmentima ravne crte.
Poligon relativnih frekvencija konstruiran je na isti način, samo što se relativne frekvencije iscrtavaju na ordinati.
Frekvencijski histogram je stepenasta figura koja se sastoji od pravokutnika, čije su osnove djelomični intervali duljine h, a visine jednake omjeru. Za konstruiranje histograma frekvencija na osi apscise iscrtavaju se djelomični intervali, a iznad njih segmenti se povlače paralelno s osi apscise na udaljenosti (visini). Površina i-tog pravokutnika jednaka je zbroju frekvencija, varijanti i-o intervala, stoga je područje histograma frekvencija jednako zbroju svih frekvencija, t.j. veličina uzorka.


Empirijska funkcija raspodjele
gdje n x- broj uzorkovanih vrijednosti manji od x; n- veličina uzorka.
22 Definirajmo osnovne pojmove matematičke statistike
.Osnovni pojmovi matematičke statistike. Opća populacija i uzorak. Varijacijske serije, statističke serije. Grupirani uzorak. Grupirane statističke serije. Poligon frekvencija. Funkcija distribucije uzorka i histogram.
Opća populacija- cijeli skup dostupnih objekata.
Uzorak- skup objekata nasumično odabranih iz opće populacije.
Zove se niz varijanti, napisan uzlaznim redoslijedom varijacijski zatim popis opcija i njihovih odgovarajućih frekvencija ili relativnih frekvencija - statističke serije: čaj odabran iz opće populacije.
Poligon frekvencije se nazivaju isprekidanom linijom čiji segmenti povezuju točke.
Histogram frekvencije naziva stepenasta figura koja se sastoji od pravokutnika, čije su osnove djelomični intervali duljine h, a visine jednake omjeru.
Primjer (empirijske) funkcije raspodjele pozvati funkciju F *(x), koji za svaku vrijednost određuje NS relativna učestalost događaja x< x.
Ako se istražuje neko kontinuirano obilježje, tada se varijacijski niz može sastojati od vrlo velikog broja brojeva. U ovom je slučaju prikladnije koristiti objedinjeni uzorak... Da bi se to dobilo, interval u kojem su obuhvaćene sve promatrane vrijednosti obilježja podijeljen je na nekoliko jednakih parcijalnih intervala duljine h, a zatim pronaći za svaki parcijalni interval n i- zbroj frekvencija varijante koja je pala i th interval.
20. Zakon velikih brojeva ne treba shvatiti kao jedan opći zakon povezan s velikim brojevima. Zakon velikih brojeva generaliziran je naziv za nekoliko teorema, iz čega proizlazi da s neograničenim povećanjem broja pokusa prosječne vrijednosti teže nekim konstantama.
To uključuje teoreme Čebiševa i Bernoulija. Čebiševljev teorem je najopćenitiji zakon velikih brojeva.
Dokaz teorema, objedinjenih pojmom "zakon velikih brojeva", temelji se na Čebiševovoj nejednakosti, koja utvrđuje vjerojatnost odstupanja od njegovih matematičkih očekivanja:
![]()
19 Pearsonova distribucija (hi - kvadrat) - raspodjela slučajne varijable
gdje su slučajne varijable X 1, X 2, ..., X n neovisni i imaju istu distribuciju N(0,1). U ovom slučaju broj pojmova, tj. n naziva se "broj stupnjeva slobode" distribucije hi-kvadrata.
Distribucija hi-kvadrata koristi se pri procjeni varijance (pomoću intervala pouzdanosti), pri testiranju hipoteza slaganja, homogenosti, neovisnosti,
Distribucija t Student's t je distribucija slučajne varijable
gdje su slučajne varijable U i x neovisna, U ima standardnu normalnu distribuciju N(0,1) i x- chi distribucija - kvadrat s n stupnjevi slobode. Pri čemu n naziva se "broj stupnjeva slobode" Studentove distribucije.
Koristi se pri procjeni matematičkih očekivanja, predviđene vrijednosti i drugih karakteristika pomoću intervala pouzdanosti, za provjeru hipoteza o vrijednostima matematičkih očekivanja, regresijskim koeficijentima,
Fisherova distribucija je distribucija slučajne varijable
Fisherova raspodjela koristi se za provjeru hipoteza o primjerenosti modela u regresijskoj analizi, o jednakosti varijanci i u drugim problemima primijenjene statistike.
18Linearna regresija je statistički alat koji se koristi za predviđanje budućih cijena na temelju prošlih podataka i obično se koristi za određivanje kada su cijene pregrijane. Metoda najmanjih kvadrata koristi se za iscrtavanje "najbolje pristajuće" ravne linije kroz niz cjenovnih bodova. Bodovi koji se koriste kao ulaz mogu biti bilo koje od sljedećih vrijednosti: otvoreno, zatvoreno, visoko, nisko,
17. Dvodimenzionalna slučajna varijabla je uređen skup dviju slučajnih varijabli ili.
Primjer: Bacaju se dvije kockice. - broj bodova ispuštenih na prvoj i drugoj kockici
Univerzalni način definiranja zakona raspodjele dvodimenzionalne slučajne varijable je funkcija raspodjele.
15.m.o Diskretne slučajne varijable
Svojstva:
1) M(C) = C, C- konstantno;
2) M(CX) = CM(x);
3) M(X 1 + X 2) = M(X 1) + M(X 2), gdje X 1, X 2- neovisne slučajne varijable;
4) M(X 1 X 2) = M(X 1)M(X 2).
Matematičko očekivanje zbroja slučajnih varijabli jednako je zbroju njihovih matematičkih očekivanja, t.j.
Matematičko očekivanje razlike slučajnih varijabli jednako je razlici njihovih matematičkih očekivanja, t.j.
Matematičko očekivanje proizvoda slučajnih varijabli jednako je umnošku njihovih matematičkih očekivanja, t.j.
Ako se sve vrijednosti slučajne varijable povećaju (smanje) za isti broj C, tada će se njezino matematičko očekivanje povećati (smanjiti) za isti broj
14. Eksponencijalna(eksponencijalna)zakon o distribuciji x ima eksponencijalni (eksponencijalni) zakon raspodjele s parametrom λ> 0, ako njegova gustoća vjerojatnosti ima oblik:
![]()
Očekivana vrijednost: .
Disperzija:.
Eksponencijalni zakon raspodjele igra važnu ulogu u teoriji redova čekanja i teoriji pouzdanosti.
13. Normalni zakon distribucije karakterizira stopa kvara a (t) ili gustoća vjerojatnosti kvarova f (t) oblika:
 , (5.36)
, (5.36)
gdje je σ standardna devijacija SV x;
m x- matematičko očekivanje SV x... Ovaj se parametar često naziva središtem raspršenja ili najvjerojatnijom vrijednošću MW. NS.
x- slučajna varijabla za koju možete uzeti vrijeme, vrijednost struje, vrijednost električnog napona i druge argumente.
Normalni zakon je zakon s dva parametra, za koji morate znati m x i σ.
Normalna raspodjela (Gaussova distribucija) koristi se za procjenu pouzdanosti proizvoda na koje utječu brojni slučajni čimbenici, od kojih svaki ne utječe značajno na rezultirajući učinak.
12. Jedinstveni zakon o distribuciji... Kontinuirana slučajna varijabla x ima ujednačen zakon raspodjele na segmentu [ a, b], ako je njegova gustoća vjerojatnosti konstantna na ovom intervalu i jednaka nuli izvan njega, tj.

Oznaka:.
Očekivana vrijednost: .
Disperzija:.
Slučajna vrijednost NS jednoliko raspoređen po segmentu naziva se slučajni broj od 0 do 1. Služi kao izvorni materijal za dobivanje slučajnih varijabli s bilo kojim zakonom distribucije. Jedinstveni zakon raspodjele koristi se u analizi pogrešaka zaokruživanja prilikom izvođenja numeričkih proračuna, u nekim slučajevima problema čekanja u redu, u statističkom modeliranju promatranja podložnih zadanoj raspodjeli.
11. Definicija. Gustoća distribucije vjerojatnosti kontinuirane slučajne varijable X naziva se funkcija f (x) Je li prva izvedenica funkcije raspodjele F (x).
Gustoća distribucije se također naziva diferencijalna funkcija... Za opis diskretne slučajne varijable, gustoća raspodjele je neprihvatljiva.
Značenje gustoće raspodjele je da pokazuje koliko se često slučajna varijabla X pojavljuje u nekom susjedstvu točke NS pri ponavljanju pokusa.
Nakon uvođenja funkcija raspodjele i gustoće raspodjele, možemo dati sljedeću definiciju kontinuirane slučajne varijable.
10. Gustoća vjerojatnosti, gustoća raspodjele vjerojatnosti slučajne varijable x, je funkcija p (x) takva da 
i za bilo koji a< b вероятность события a < x < b равна
.
Ako je p (x) kontinuiran, tada je za dovoljno mali ∆x vjerojatnost nejednakosti x< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
i, ako je F (x) diferencijabilan, tada ![]()
Predavanje 13. Koncept statističkih procjena slučajnih varijabli
Neka je poznata statistička raspodjela frekvencija kvantitativnog atributa X. Označimo s brojem opažanja pri kojima je promatrana vrijednost atributa manja od x, a s n - ukupan broj opažanja. Očigledno je da je relativna učestalost događaja X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Empirijska funkcija raspodjele(funkcija distribucije uzorka) je funkcija koja za svaku vrijednost x određuje relativnu učestalost događaja X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
Za razliku od empirijske funkcije raspodjele uzorka, naziva se funkcija raspodjele opće populacije teorijska funkcija raspodjele. Razlika između ovih funkcija je u tome što teorijska funkcija definira vjerojatnost događaji X< x, тогда как эмпирическая – relativna frekvencija istog događaja.
Kako n raste, relativna učestalost događaja X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Svojstva empirijske funkcije raspodjele:
1) Vrijednosti empirijske funkcije pripadaju segmentu
2) - funkcija koja se ne smanjuje
3) Ako je najmanja opcija, tada = 0 za, ako je najveća opcija, onda = 1 za.
Empirijska funkcija raspodjele uzorka koristi se za procjenu teorijske funkcije raspodjele opće populacije.
Primjer... Konstruirajmo empirijsku funkciju za raspodjelu uzorka:
| Varijante | |||
| Učestalosti |
Pronađi veličinu uzorka: 12 + 18 + 30 = 60. Najmanja opcija je 2, dakle = 0 za x £ 2. Vrijednost x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Dakle, tražena empirijska funkcija ima oblik:
Najvažnija svojstva statističkih procjena
Neka bude potrebno proučiti neke kvantitativne značajke opće populacije. Pretpostavimo da je iz teorijskih razmatranja bilo moguće ustanoviti koji raspodjela ima karakteristiku i potrebno je ocijeniti parametre po kojima se određuje. Na primjer, ako se ispitivana osobina normalno distribuira u općoj populaciji, tada morate procijeniti matematička očekivanja i standardnu devijaciju; ako obilježje ima Poissonovu distribuciju, tada je potrebno procijeniti parametar l.
Obično su dostupni samo uzorci, na primjer, vrijednosti kvantitativne osobine dobivene kao rezultat n neovisnih opažanja. S obzirom na neovisne slučajne varijable, možemo to reći pronaći statističku procjenu nepoznatog parametra teorijske raspodjele znači pronaći funkciju promatranih slučajnih varijabli, koja daje približnu vrijednost procijenjenog parametra. Na primjer, za procjenu matematičkog očekivanja normalne distribucije, ulogu funkcije ima aritmetička sredina
Da bi statističke procjene dale točne aproksimacije procijenjenih parametara, moraju zadovoljiti određene zahtjeve, među kojima su najvažniji zahtjevi nepristranost i dosljednost procjene.
Dopustiti biti statistička procjena nepoznatog parametra teorijske raspodjele. Neka se nađe procjena za uzorak veličine n. Ponovimo iskustvo, tj. izdvajamo iz opće populacije još jedan uzorak iste veličine i prema njegovim podacima dobivamo drugačiju procjenu. Ponavljajući eksperiment više puta, dobivamo različite brojeve. Rezultat se može promatrati kao slučajna varijabla, a brojevi kao njegove moguće vrijednosti.
Ako procjena daje približnu vrijednost u izobilju, tj. svaki broj veći od prave vrijednosti, tada je, kao posljedica, matematičko očekivanje (prosječna vrijednost) slučajne varijable veće od :. Slično, ako daje procjenu sa nedostatkom, tada.
Stoga bi uporaba statističke procjene, čije matematičko očekivanje nije jednako parametru koji se procjenjuje, dovela do sustavnih (jednoznamenkastih) pogrešaka. Ako, naprotiv, to jamči od sustavnih pogrešaka.
Nepristran naziva se statistička procjena, čije je matematičko očekivanje jednako procijenjenom parametru za bilo koju veličinu uzorka.
Raseljeno je procjena koja ne zadovoljava ovaj uvjet.
Nepristranost procjene još ne jamči dobru aproksimaciju parametra koji se procjenjuje, budući da su moguće vrijednosti vrlo raštrkano oko njegove srednje vrijednosti, tj. varijacija može biti značajna. U ovom slučaju, procjena pronađena na primjerima iz jednog uzorka može se pokazati značajno udaljenom od srednje vrijednosti, a time i od samog procijenjenog parametra.
Učinkovit je statistička procjena koju za datu veličinu uzorka n ima najmanja moguća varijacija .
Prilikom razmatranja uzoraka velike veličine, zahtjev se nameće statističkim procjenama dosljednost .
Bogati je statistička procjena koja, za n® ¥, vjerovatno teži parametru koji se procjenjuje. Na primjer, ako varijansa nepristrane procjene teži nuli kao n® ¥, tada je i ta procjena dosljedna.
Određivanje empirijske funkcije raspodjele
Neka je $ X $ slučajna varijabla. $ F (x) $ - funkcija raspodjele zadane slučajne varijable. Izvest ćemo $ n $ pokuse na zadanoj slučajnoj varijabli pod istim neovisnim uvjetima. U ovom slučaju dobivamo niz vrijednosti $ x_1, \ x_2 \ $, ..., $ \ x_n $, koji se naziva odabirom.
Definicija 1
Svaka vrijednost $ x_i $ ($ i = 1,2 \ $, ..., $ \ n $) naziva se varijantom.
Jedna od procjena teorijske funkcije raspodjele je empirijska funkcija raspodjele.
Definicija 3
Empirijska funkcija raspodjele $ F_n (x) $ je funkcija koja za svaku vrijednost $ x $ određuje relativnu učestalost događaja $ X \
gdje je $ n_x $ broj opcija manji od $ x $, $ n $ je veličina uzorka.
Razlika između empirijske funkcije i teorijske je u tome što teorijska funkcija određuje vjerojatnost događaja $ X
Svojstva empirijske funkcije raspodjele
Razmotrimo sada nekoliko osnovnih svojstava funkcije raspodjele.
Raspon vrijednosti funkcije $ F_n \ lijevo (x \ desno) $ je segment $$.
$ F_n \ lijevo (x \ desno) $ funkcija koja se ne smanjuje.
$ F_n \ left (x \ right) $ je lijeva kontinuirana funkcija.
$ F_n \ left (x \ right) $ je komadno konstantna funkcija i povećava se samo na vrijednosnim mjestima slučajne varijable $ X $
Neka je $ X_1 $ najmanja, a $ X_n $ najveća opcija. Tada je $ F_n \ lijevo (x \ desno) = 0 $ za $ (x \ le X) _1 $ i $ F_n \ lijevo (x \ desno) = 1 $ za $ x \ ge X_n $.
Uvedimo teorem koji povezuje teorijsku i empirijsku funkciju.
Teorem 1
Neka je $ F_n \ left (x \ right) $ empirijska funkcija raspodjele, a $ F \ left (x \ right) $ teoretska funkcija raspodjele općeg uzorka. Tada vrijedi jednakost:
\ [(\ mathop (lim) _ (n \ do \ infty) (| F) _n \ lijevo (x \ desno) -F \ lijevo (x \ desno) | = 0 \) \]
Primjeri problema za pronalaženje empirijske funkcije raspodjele
Primjer 1
Neka distribucija uzorka ima sljedeće podatke zabilježene pomoću tablice:
Slika 1.
Pronađite veličinu uzorka, sastavite empirijsku funkciju raspodjele i iscrtajte je.
Veličina uzorka: $ n = 5 + 10 + 15 + 20 = 50 $.
Prema svojstvu 5 imamo da je za $ x \ le 1 $ F_n \ lijevo (x \ desno) = 0 $, a za $ x> 4 $ $ F_n \ lijevo (x \ desno) = 1 $.
Vrijednost $ x
Vrijednost $ x
Vrijednost $ x
Tako dobivamo:

Slika 2.

Slika 3.
Primjer 2
Iz gradova središnjeg dijela Rusije nasumično je odabrano 20 gradova za koje su dobiveni sljedeći podaci o troškovima putovanja u javnom prijevozu: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12 , 15, 14, 15, 13, 13, 12, 12, 15, 14, 14.
Napravite empirijsku funkciju distribucije za dati uzorak i sastavite njezin graf.
Zapišimo uzorke uzlazno i izračunajmo učestalost svake vrijednosti. Dobivamo sljedeću tablicu:
Slika 4.
Veličina uzorka: $ n = 20 $.
Prema svojstvu 5, to je za $ x \ le 12 $ F_n \ lijevo (x \ desno) = 0 $, a za $ x> 15 $ $ F_n \ lijevo (x \ desno) = 1 $.
Vrijednost $ x
Vrijednost $ x
Vrijednost $ x
Tako dobivamo:

Slika 5.
Nacrtajmo empirijsku distribuciju:

Slika 6.
Originalnost: 92,12 USD \% $.
Naučite što je opće pravilo. U kemiji je EF najjednostavniji način za opisivanje spoja - zapravo, to je popis elemenata koji tvore spoj, uzimajući u obzir njihov postotak. Valja napomenuti da ova najjednostavnija formula ne opisuje narudžba atoma u spoju, jednostavno označava od kojih se elemenata sastoji. Na primjer:
- Spoj koji se sastoji od 40,92% ugljika; 4,58% vodika i 54,5% kisika imat će empirijsku formulu C 3 H 4 O 3 (o primjeru kako pronaći EF ovog spoja bit će riječi u drugom dijelu).
Shvatite pojam "postotak"."Postotak" se odnosi na postotak svakog pojedinačnog atoma u cijelom spoju koji se razmatra. Da biste pronašli empirijsku formulu za spoj, morate znati postotak spoja. Ako pronađete empirijsku formulu za svoju domaću zadaću, vjerojatno će se dati postoci.
- Da bi se utvrdio postotak kemijskog spoja u laboratoriju, on se podvrgava nekim fizičkim pokusima, a zatim kvantitativnoj analizi. Ako niste u laboratoriju, ne morate raditi ove pokuse.
Imajte na umu da se morate nositi s atomima grama. Atom od grama je određena količina tvari čija je masa jednaka atomskoj masi. Da biste pronašli gram gram, morate koristiti sljedeću jednadžbu: Postotak elementa u spoju podijeljen je s atomskom masom elementa.
- Recimo, na primjer, da imamo spoj koji sadrži 40,92% ugljika. Atomska masa ugljika je 12, pa će naša jednadžba imati 40,92 / 12 = 3,41.
Znati pronaći atomski omjer. Radeći sa spojem, dobit ćete više od jednog grama atoma. Nakon što pronađete sve atome grama vašeg spoja, pogledajte ih. Da biste pronašli atomski omjer, morat ćete odabrati najmanji gram gram koji ste izračunali. Tada ćete morati podijeliti sve gram-atome na najmanji gram-atom. Na primjer:
- Recimo da radite sa spojem koji sadrži tri gram-atoma: 1,5; 2 i 2.5. Najmanji od ovih brojeva je 1,5. Stoga, da biste pronašli omjer atoma, morate podijeliti sve brojeve s 1,5 i staviti znak omjera između njih : .
- 1,5 / 1,5 = 1,2 / 1,5 = 1,33. 2,5 / 1,5 = 1,66. Stoga je omjer atoma 1: 1,33: 1,66 .
Shvatite kako pretvoriti vrijednosti omjera atoma u cijele brojeve. Prilikom zapisivanja empirijske formule morate koristiti cijele brojeve. To znači da ne možete koristiti brojeve poput 1,33. Nakon što pronađete omjer atoma, trebate pretvoriti razlomljene brojeve (poput 1,33) u cijele brojeve (poput 3). Da biste to učinili, morate pronaći cijeli broj, pomnožen s kojim svaki broj atomskog omjera dobijete cijele brojeve. Na primjer:
- Pokušajte 2. Pomnožite brojeve atomskih omjera (1, 1,33 i 1,66) s 2. Dobit ćete 2, 2,66 i 3,32. Ovo nisu cijeli brojevi pa se 2 ne uklapa.
- Pokušajte 3. Ako pomnožite 1, 1,33 i 1,66 s 3, dobit ćete 3, 4 i 5, respektivno. Prema tome, atomski omjer cijelih brojeva ima oblik 3: 4: 5 .
Kao što znate, zakon raspodjele slučajne varijable može se specificirati na različite načine. Diskretna slučajna varijabla može se specificirati pomoću distribucijskog niza ili integralne funkcije, a kontinuirana slučajna varijabla - pomoću integralne ili diferencijalne funkcije. Razmotrimo selektivne analoge ove dvije funkcije.
Neka postoji skup uzoraka vrijednosti nekog slučajnog volumena  i svakoj opciji iz ovog agregata dodjeljuje se njezina učestalost. Neka dalje,
i svakoj opciji iz ovog agregata dodjeljuje se njezina učestalost. Neka dalje,  - neki pravi broj, i
- neki pravi broj, i  - broj uzorkovanih vrijednosti slučajne varijable
- broj uzorkovanih vrijednosti slučajne varijable  manje
manje  . Zatim broj
. Zatim broj  je učestalost vrijednosti količine uočene u uzorku x manje
je učestalost vrijednosti količine uočene u uzorku x manje  ,
oni. učestalost pojavljivanja događaja
,
oni. učestalost pojavljivanja događaja 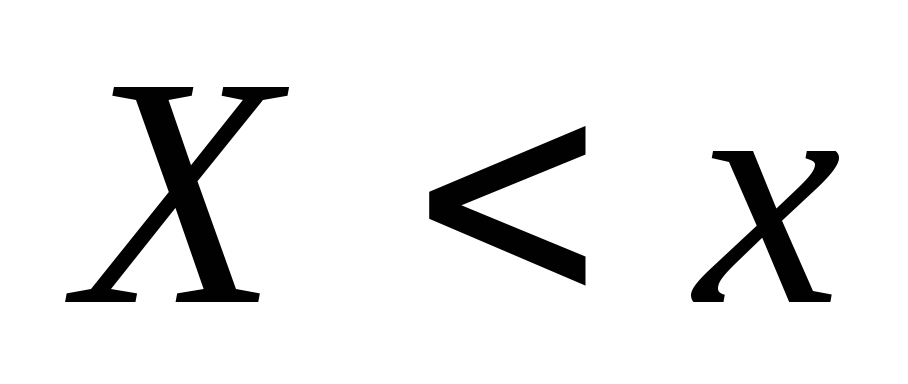 ... Kad se promijeni x u općem slučaju količina
... Kad se promijeni x u općem slučaju količina  ... To znači da je relativna frekvencija
... To znači da je relativna frekvencija  je funkcija argumenta
je funkcija argumenta  ... A budući da se ta funkcija nalazi prema podacima uzorka dobivenim kao rezultat pokusa, naziva se selektivna ili empirijski.
... A budući da se ta funkcija nalazi prema podacima uzorka dobivenim kao rezultat pokusa, naziva se selektivna ili empirijski.
Definicija 10.15. Empirijska funkcija raspodjele(funkcija raspodjele uzorka) naziva se funkcija  određujući za svaku vrijednost x relativna učestalost događaja
određujući za svaku vrijednost x relativna učestalost događaja  .
.
 (10.19)
(10.19)
Za razliku od empirijske funkcije raspodjele uzorka, funkcija raspodjele Ž(x) opće populacije naziva se teorijska funkcija raspodjele... Razlika među njima je u tome što teoretska funkcija Ž(x)
određuje vjerojatnost događaja  , a empirijsko - relativna učestalost istog događaja. Bernoullijev teorem implicira
, a empirijsko - relativna učestalost istog događaja. Bernoullijev teorem implicira
 ,
,
 (10.20)
(10.20)
oni. u cjelini  vjerojatnost
vjerojatnost  i relativnu učestalost događaja
i relativnu učestalost događaja  , tj.
, tj.  se međusobno malo razlikuju. To već implicira svrsishodnost korištenja empirijske funkcije raspodjele uzorka za približan prikaz teorijske (integralne) funkcije raspodjele opće populacije.
se međusobno malo razlikuju. To već implicira svrsishodnost korištenja empirijske funkcije raspodjele uzorka za približan prikaz teorijske (integralne) funkcije raspodjele opće populacije.
Funkcija  i
i  imaju ista svojstva. To proizlazi iz definicije funkcije.
imaju ista svojstva. To proizlazi iz definicije funkcije. 
Svojstva  :
:

Primjer 10.4. Konstruirajte empirijsku funkciju za zadanu distribuciju uzorka:
|
Varijante | |||
|
Učestalosti |


Riješenje: Pronađite veličinu uzorka n=
12 + 18 + 30 = 60. Najmanja opcija  , Slijedom toga,
, Slijedom toga,  na
na  ... Značenje
... Značenje  , naime
, naime  promatrano je 12 puta, dakle:
promatrano je 12 puta, dakle:
 =
= na
na  .
.
Značenje x<
10, naime  i
i  promatrani su 12 + 18 = 30 puta, dakle,
promatrani su 12 + 18 = 30 puta, dakle,  =
=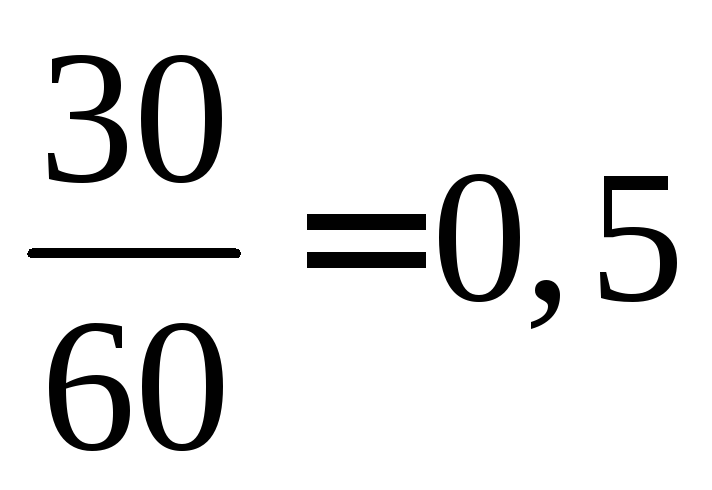 na
na  ... Na
... Na 
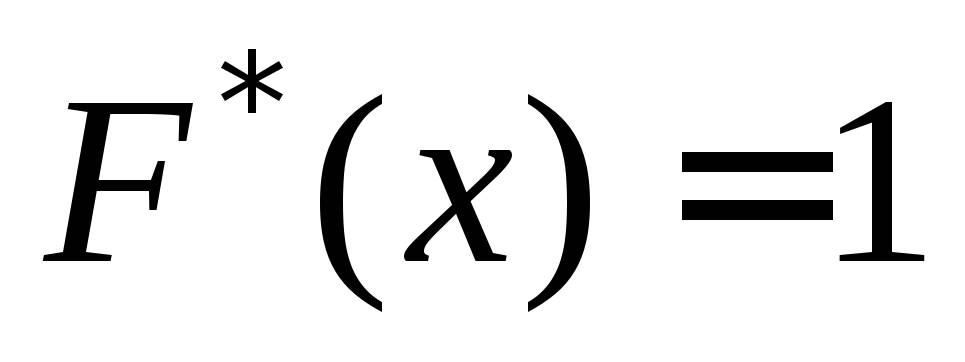 .
.
Tražena empirijska funkcija distribucije:
 =
=
Raspored  prikazan je na Sl. 10.2
prikazan je na Sl. 10.2
R  je. 10.2
je. 10.2
ispitna pitanja
1. Koji su glavni zadaci koje rješava matematička statistika? 2. Opća i uzorkovana populacija? 3. Dajte definiciju veličine uzorka. 4. Koji se uzorci nazivaju reprezentativnim? 5. Pogreške reprezentativnosti. 6. Glavne metode uzorkovanja. 7. Pojmovi frekvencije, relativne frekvencije. 8. Pojam statističkog niza. 9. Zapišite Sturgesovu formulu. 10. Formulirajte koncepte raspona uzorka, medijane i načina. 11. Frekvencijski poligon, histogram. 12. Koncept točkaste procjene uzorkovane populacije. 13. Pristrana i nepristrana procjena bodova. 14. Formulirajte pojam srednje vrijednosti uzorka. 15. Formulirajte koncept varijance uzorka. 16. Formulirajte koncept standardne devijacije uzorka. 17. Formulirajte koncept uzorka koeficijenta varijacije. 18. Formulirajte pojam geometrijske sredine uzorka.
