Correlation coefficient equal to 1 means that. Statistics and data processing in psychology (continued)
»Statistics
Statistics and data processing in psychology
(continued)
Correlation analysis
When studying correlationstry to establish whether there is any connection between the two indicators in one sample (for example, between the growth and weight of children or between the level IQ.and school performance) or between two different samples (for example, when comparing couples of twins), and if this connection exists, then an increase in one indicator is accompanied by an increase (positive correlation) or a decrease (negative correlation) of another.
In other words, the correlation analysis helps to establish whether it is possible to predict the possible values \u200b\u200bof one indicator, knowing the quantity of the other.
Until now, when analyzing the results of our experience in studying the action of marijuana, we deliberately ignored such an indicator as the reaction time. Meanwhile, it would be interesting to check whether there is a connection between the efficiency of reactions and their speed. This would allow, for example, to argue that the person is slowing, the more accurate and more effectively will be his actions and vice versa.
For this purpose, two different methods can be used: a parametric method for calculating the anti-purson coefficient (R) and calculating the coefficient of correlation of spirmen's ranks (R S), which is applied to the ordinal data, i.e. It is non-parametric. However, we will understand first in the fact that such a correlation coefficient is.
Correlation coefficient
The correlation coefficient is a value that can vary from +1 to -1. In the case of a complete positive correlation, this coefficient is plus 1, and with a complete negative - minus 1. The direct line corresponds to the graph of the intersection of the values \u200b\u200bof each data pair:

In the case, if these points are not built in a straight line, and form a "cloud", the correlation coefficient in absolute value becomes less than the unit and as this cloud rounded it is approaching zero:
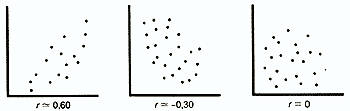
If the correlation coefficient is 0, both variables are completely independent of each other.
In the humanitarian science, the correlation is considered strong if its coefficient is above 0.60; If it exceeds 0.90, the correlation is considered very strong. However, in order to make conclusions about the links between variables, the sample size is of great importance: than the sample is greater, the more expensive the value of the correlation coefficient. There are tables with critical values \u200b\u200bof the Brave-Pearson and Spearman correlation coefficient for a different number of degrees of freedom (it is equal to the number of pairs less than 2, i.e. n-2). Only if the correlation coefficients are larger than these critical values, they can be considered reliable. So, in order for the correlation coefficient of 0.70 to be reliable, no less than 8 pairs of data should be taken into the analysis (h. \u003d N.-2 \u003d 6) when calculating R (see Table 4 in Appendix) and 7 pairs of data (H \u003d n-2 \u003d5) when calculating R s (Table 5 in the Appendix).
I would like to emphasize once again that the essence of these two coefficients is somewhat different. The negative coefficient of R indicates that efficiency is most often higher than the reaction time less, whereas when calculating the R S coefficient, it was necessary to check whether the faster testes always react more accurately, and more slowly - less accurately.
Correlation Coefficient Brave-Pearson (R) - this is an etoparametric indicator for calculating the average and standard deviations of the results of two dimensions. At the same time, they use the formula (from different authors it may look different)
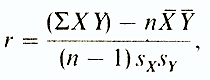
where σ. XY -the amount of data from each pair;
n-number of couples;
X - average for variable data X;
Y. -
middle for data variable Y.
S X -standard deviation for distribution x;
S y -standard deviation for distribution w.
Spearman's rang correlation coefficient (r S. ) - This is a non-parametric indicator, with which they try to identify the relationship between the ranks of the corresponding values \u200b\u200bin two rows of measurements.
This coefficient is easier to calculate, but the results are less accurate than when using R. This is due to the fact that when calculating the coefficient of spirit, the order of data is used, and not their quantitative characteristics and intervals between classes.
The fact is that when using the coefficient of correlation of spirmen's rank (RS), it is checked only whether data ranking for any sample is the same as in a number of other data for this sample, pairwise connected with the first (for example, whether the same " Rank "Students when passing as psychology and mathematics, or even with two different psychology teachers?). If the coefficient is close to +1, this means that both rows are practically coincided, and if this coefficient is close to -1, we can talk about full inverse addiction.
Coefficient r S.calculate by formula
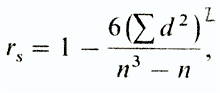
where d.- The difference between the ranks of the conjugate signs of signs (regardless of its sign), and the number of pairs.
Usually this non-parametric test is used in cases where you need to make some conclusions not so much about intervalsbetween data, how much about their rankand even when the distribution curves are too asymmetric and do not allow the use of parametric criteria as the R coefficient (in these cases it is necessary to turn quantitative data into ordinal).
Summary
So, we reviewed various parametric and non-parametric statistical methods used in psychology. Our review was very superficial, and his main task was that the reader would understand that statistics were not as terrible, as it seems, and requires mainly common sense. We remind you that the data of the "experience" with which we dealt here are, fictional and cannot serve as a basis for any conclusions. However, such an experiment would cost really spend. Since for this experience, a purely classical technique was chosen, the same statistical analysis could be used in a variety of different experiments. In any case, it seems to us that we have outlined some major directions that may be useful to those who do not know where to start a statistical analysis of the results obtained.
Literature
- Godfrau J.What is psychology. - M., 1992.
- Chatillon G.,1977. Statistique en Sciencees Humaines, Trois-Rivieres, ED. SMG.
- Gilbert N ..1978. Statistiques, Montreal, ED. HRW.
- MORONEY M.J.,1970. Comprender La Statistique, Verviers, Gerard et Cie.
- Siegel S.,1956. NON-PARAMETRIC STATISTIC, NEW YORK, MACGRAW-HILL BOOK CO.
Appendix Table
Notes.1) For large samples or level of significance, less than 0.05 should be referred to tables in statistics allowances.
2) Tables of values \u200b\u200bof other non-parametric criteria can be found in special manuals (see bibliography).
| Table 1. Criteria values t.Student | |
| h. | 0,05 |
| 1 | 6,31 |
| 2 | 2,92 |
| 3 | 2,35 |
| 4 | 2,13 |
| 5 | 2,02 |
| 6 | 1,94 |
| 7 | 1,90 |
| 8 | 1,86 |
| 9 | 1,83 |
| 10 | 1,81 |
| 11 | 1,80 |
| 12 | 1,78 |
| 13 | 1,77 |
| 14 | 1,76 |
| 15 | 1,75 |
| 16 | 1,75 |
| 17 | 1,74 |
| 18 | 1,73 |
| 19 | 1,73 |
| 20 | 1,73 |
| 21 | 1,72 |
| 22 | 1,72 |
| 23 | 1,71 |
| 24 | 1,71 |
| 25 | 1,71 |
| 26 | 1,71 |
| 27 | 1,70 |
| 28 | 1,70 |
| 29 | 1,70 |
| 30 | 1,70 |
| 40 | 1,68 |
| ¥ | 1,65 |
| Table 2. Values \u200b\u200bof the criterion χ 2 | |
| h. | 0,05 |
| 1 | 3,84 |
| 2 | 5,99 |
| 3 | 7,81 |
| 4 | 9,49 |
| 5 | 11,1 |
| 6 | 12,6 |
| 7 | 14,1 |
| 8 | 15,5 |
| 9 | 16,9 |
| 10 | 18,3 |
| Table 3. Reliable Z values | |
| r | Z. |
| 0,05 | 1,64 |
| 0,01 | 2,33 |
| Table 4. Reliable (critical) values \u200b\u200bR | ||
| h \u003d (N-2) | p \u003d.0,05 (5%) | |
| 3 | 0,88 | |
| 4 | 0,81 | |
| 5 | 0,75 | |
| 6 | 0,71 | |
| 7 | 0,67 | |
| 8 | 0,63 | |
| 9 | 0,60 | |
| 10 | 0,58 | |
| 11 | 0.55 | |
| 12 | 0,53 | |
| 13 | 0,51 | |
| 14 | 0,50 | |
| 15 | 0,48 | |
| 16 | 0,47 | |
| 17 | 0,46 | |
| 18 | 0,44 | |
| 19 | 0,43 | |
| 20 | 0,42 | |
| Table 5. Reliable (critical) values \u200b\u200bR s | |
| h \u003d (N-2) | p \u003d.0,05 |
| 2 | 1,000 |
| 3 | 0,900 |
| 4 | 0,829 |
| 5 | 0,714 |
| 6 | 0,643 |
| 7 | 0,600 |
| 8 | 0,564 |
| 10 | 0,506 |
| 12 | 0,456 |
| 14 | 0,425 |
| 16 | 0,399 |
| 18 | 0,377 |
| 20 | 0,359 |
| 22 | 0,343 |
| 24 | 0,329 |
| 26 | 0,317 |
| 28 | 0,306 |
When studying correlationstry to establish whether there is any connection between the two indicators in one sample (for example, between the growth and weight of children or between the level IQ.and school performance) or between two different samples (for example, when comparing couples of twins), and if this connection exists, then an increase in one indicator is accompanied by an increase (positive correlation) or a decrease (negative correlation) of another.
In other words, the correlation analysis helps to establish whether it is possible to predict the possible values \u200b\u200bof one indicator, knowing the quantity of the other.
Until now, when analyzing the results of our experience in studying the action of marijuana, we deliberately ignored such an indicator as the reaction time. Meanwhile, it would be interesting to check whether there is a connection between the efficiency of reactions and their speed. This would allow, for example, to argue that the person is slowing, the more accurate and more effectively will be his actions and vice versa.
For this purpose, two different methods can be used: a parametric method for calculating the brave coefficient - Pearson (R)and calculating the correlation coefficient of alcoholic ranks (R. s. ), which is applied to ordinal data, i.e. is non-parametric. However, we will understand first in the fact that such a correlation coefficient is.
Correlation coefficient
The correlation coefficient is the value that can vary from -1 to 1. In the case of a complete positive correlation, this coefficient is plus 1, and with a complete negative - minus 1. The straight line passes through the intersection points of each pair Data:
Variable

In the case, if these points are not built in a straight line, and form a "cloud", the correlation coefficient in absolute value becomes less than the unit and as this cloud rounded it is approaching zero:

If the correlation coefficient is 0, both variables are completely independent of each other.
In the humanitarian science, the correlation is considered strong if its coefficient is above 0.60; If it exceeds 0.90, the correlation is considered very strong. However, in order to make conclusions about the links between variables, the sample size is of great importance: than the sample is greater, the more expensive the value of the correlation coefficient. There are tables with critical values \u200b\u200bof the Brave-Pearson and Spearman correlation coefficient for a different number of degrees of freedom (it is equal to the number of pairs less than 2, i.e. n.-2). Only if the correlation coefficients are larger than these critical values, they can be considered reliable. So, in order for the correlation coefficient of 0.70 to be reliable, no less than 8 pairs of data should be taken into the analysis ( = p -2 = 6) when calculating r.(Table. V.4) and 7 pairs of data ( \u003d P -2 \u003d 5) when calculating r. s. (Table 5 in Appendix B. 5).
Brave coefficient - Pearson
To calculate this coefficient, the following formula is used (from different authors it may look different):

where XY. - the amount of data from each pair;
n. - number of pairs;
- middle for data variable X.;
Middle for data variable Y.;
S. H. - x.;
s. Y. - standard deviation for distribution y
Now we can use this coefficient in order to establish whether there is a connection between the response time of the subjects and the effectiveness of their actions. Take, for example, the background level of the control group.

n.= 15 15,8 13,4 = 3175,8;
(n. – 1)S. x. S. y. = 14 3,07 2,29 = 98,42;
r.
=

The negative value of the correlation coefficient may mean that the larger the reaction time, the lower the efficiency. However, it is too small in order to talk about a reliable connection between this two variables.
nXY \u003d.………
(N.- 1) S. X. S. Y. = ……
What conclusion can be made of these results? If you think that there is a connection between the variables, then what is it - direct or reverse? It is reliable [see Table. 4 (in Supplement B. 5) with critical values r.]?
Spearman's rank correlation coefficientr. s.
This coefficient is easier to calculate, but the results are less accurate than when using r.This is due to the fact that when calculating the coefficient of spirit, the order of data is used, and not their quantitative characteristics and intervals between classes.
The fact is that when using the rank correlation coefficient Spearmene(R. s. ) check only whether data ranking for any sample is the same as in a number of other data for this sample, pairwise connected with the first (for example, students will be equally "ranked" when they pass as psychology and mathematics, or Even with two different teachers of psychology?). If the coefficient is close to + 1, this means that both rows are almost coincided, and if this coefficient is close to - 1, you can talk about full inverse addiction.
Coefficient r. s. calculate by formula

where d-the difference between the ranks of the conjugate signs of signs (regardless of its sign), and n.- Paras.
Usually this non-parametric test is used in cases where you need to make some conclusions not so much about intervalsbetween data, how much about their rankand then when the distribution curves are too asymmetric and do not allow using such parametric criteria as the coefficient r.(In these cases, it is necessary to turn quantitative data into ordinal).
Since this is the case with the distribution of the values \u200b\u200bof the efficiency and time of the reaction in the experimental group after exposure, it is possible to repeat the calculations that you have already done for this group, only now is not for the coefficient r., and for the indicator r. s. . This will allow you to see how much these two indicators differ *.

* It should be remembered that
1) For the number of hits, the 1st rank corresponds to the highest, and the 15th low performance, whereas for the reaction time the 1st rank corresponds to the shortest time, and the 15th long time;
2) EX AEQUO data attached average rank.

Thus, as in the case of the coefficient r,received positive, although unreliable, result. What of the two results is believable: r \u003d.-0.48 or r. s. \u003d +0.24? This question can only stand if the results are reliable.
I would like to emphasize once again that the essence of these two coefficients is somewhat different. Negative coefficient r.indicates that efficiency is most often higher than the reaction time less, whereas when calculating the coefficient r. s. it was necessary to check whether the faster subjects always react more accurately, and slower - less accurately.
Since the experimental group after exposure was obtained a coefficient r. s. , equal 0.24, such a tendency here is obviously not traced. Try to figure it out in your own data for the control group after exposure, knowing that d. 2 = 122,5:
; Significantly?
What is your conclusion? ...........................................................................................................
…………………………………………………………………………………………………………………….
So, we reviewed various parametric and non-parametric statistical methods used in psychology. Our review was very superficial, and his main task was that the reader would understand that statistics were not as terrible, as it seems, and requires mainly common sense. We remind you that the data of the "experience" with which we dealt here are, fictional and cannot serve as a basis for any conclusions. However, such an experiment would cost really spend. Since for this experience, a purely classical technique was chosen, the same statistical analysis could be used in a variety of different experiments. In any case, it seems to us that we have outlined some major directions that may be useful to those who do not know where to start a statistical analysis of the results obtained.
There are three main partitions of statistics: descriptive statistics, inductive statistics and correlation analysis.
7.3.1. Correlation and determination coefficients.You can quantify tight communication between factors and her food(Direct or reverse), calculated:
1) if it is necessary to determine the wearer relationship of the relationship between two factors - pair coefficientcorrelation: at 7.3.2 and 7.3.3, the calculation operations of the paired linear coefficient of Correlation on BRASH-Purson ( r.) and the pair rank coefficient of correlation in spirit ( r.);
2) if we want to determine the relationship between two factors, but this relationship is clearly non-linear correlantion ;
3) if we want to determine the relationship between one factor and some combination of other factors - then (or, that the same, the "multiple correlation coefficient");
4) if we want to identify the connection of one factor only with a specific one, which is included in the group factors affecting the first, for which it is necessary to consider the influence of all other factors unchanged - private (partial) correlation coefficient .
Any correlation coefficient (R, R) cannot at the absolute value exceed 1, that is, -1< r (r) < 1). Если получено значение 1, то это значит, что рассматриваемая зависимость не статистическая, а функциональная, если 0 - корреляции нет вообще.
The sign in the correlation coefficient determines the focus of communication: the "+" sign (or the absence of a sign) means that the connection straight (positive), the sign "-" - that the connection inverse (negative). No relationship has no relation to the tightness of the connection
The correlation coefficient characterizes a statistical relationship. But it is often necessary to identify another type of addiction, namely: what is the contribution of some factor in the formation of another factor associated with it. This kind of dependence with some part of the convention is characterized coefficient of determination (D. ) defined by the formula D. \u003d R 2 '100% (where R is a correlation coefficient of BRASH-Purson, see 7.3.2). If the measurements were carried out in scale scale (rank scale), With some damage to reliability, it is possible to substitute the value of R in the formula R (the correlation coefficient on the spirmetue, see 7.3.3).
For example, if we obtained as a characteristic of the dependence of the factor b from the factor and the correlation coefficient R \u003d 0.8 or R \u003d -0.8, then d \u003d 0.8 2 '100% \u003d 64%, that is, about 2 ½ 3. Consequently, the contribution of factor A and its changes to the formation of factor B is approximately 2 ½ 3 From the total contribution of all factors at all.
7.3.2. The correlation coefficient on Brave-Pearson. The procedure for calculating the Correlation coefficient on BRASH-Purson ( r. ) It can only be used in cases where communication is considered based on samples that have a normal frequency distribution ( normal distribution ) and the measurements obtained in the ranges of intervals or relationships. The calculated formula of this correlation coefficient:
å ( x. I -) ( y. I -)
R. = .
n × s x × s y
What shows the correlation coefficient? First, the sign in the correlation coefficient shows the focus of communication, namely: the sign "-" indicates that the connection inverse, or negative (There is a tendency: with a decrease of the values \u200b\u200bof one factor, the corresponding values \u200b\u200bof the other factor are growing, and with increasing - decrease), and the lack of a sign or sign "+" indicate straight, or positivecommunications (there is a tendency: with an increase in the values \u200b\u200bof the same factor, the values \u200b\u200bof the other are increasing, and decreased with a decrease). Secondly, the absolute (independent of the sign) the magnitude of the correlation coefficient speaks of the tightness (strength) of communication. It is considered (sufficiently conditionally): at the values \u200b\u200bof R< 0,3 корреляция very weak, often it is simply not taken into account, at 0.3 £ r< 5 корреляция weak, at 0.5 £ r< 0,7) - average, at 0.7 £ R £ 0.9) - strong And finally, at R\u003e 0.9 - very strong.In our case (R "0.83) the relationship is reverse (negative) and strong.
Recall: the values \u200b\u200bof the correlation coefficient can be in the range from -1 to +1. The output value of R for these limits indicates that in the calculations error is allowed . If a r. \u003d 1, this means that the relationship is not statistical, but the functional - which in sports, biology, medicine practically does not happen. Although with a small amount of measurements, the random selection of values, which gives a picture of the functional communication, is possible, but this case is the less likely, the greater the amount of the comparatable samples (N), that is, the number of pairs of compared measurements.
The calculated table (Table 7.1) is built according to the formula.
Table 7.1.
Calculation table for computing on BRASH-Purse
| X I. | Y I. | (x. I -) | (x. I -) 2 | (y. I -) | (y. I -) 2 | (x. I -) ( y. I -) |
| 13,2 | 4,75 | 0,2 | 0,04 | –0,35 | 0,1225 | – 0,07 |
| 13,5 | 4,7 | 0,5 | 0,25 | – 0,40 | 0,1600 | – 0,20 |
| 12,7 | 5,10 | – 0,3 | 0,09 | 0,00 | 0,0000 | 0,00 |
| 12,5 | 5,40 | – 0,5 | 0,25 | 0,30 | 0,0900 | – 0,15 |
| 13,0 | 5,10 | 0,0 | 0,00 | 0,00 | 0.0000 | 0,00 |
| 13,2 | 5,00 | 0,1 | 0,01 | – 0,10 | 0,0100 | – 0,02 |
| 13,1 | 5,00 | 0,1 | 0,01 | – 0,10 | 0,0100 | – 0,01 |
| 13,4 | 4,65 | 0,4 | 0,16 | – 0,45 | 0,2025 | – 0,18 |
| 12,4 | 5,60 | – 0,6 | 0,36 | 0,50 | 0,2500 | – 0,30 |
| 12,3 | 5,50 | – 0,7 | 0,49 | 0,40 | 0,1600 | – 0,28 |
| 12,7 | 5,20 | –0,3 | 0,09 | 0,10 | 0,0100 | – 0,03 |
| åx i \u003d 137 \u003d 13.00 | Åy i \u003d 56,1 \u003d 5.1 | å( x. I -) 2 \u003d \u003d 1.78 | å( y. I -) 2 \u003d \u003d 1,015 | å( x. I -) ( y. I -) \u003d -1.24 |
Insofar as s. x \u003d ï ï = ï ï» 0.42, A.
s. y \u003d. ï ï» 0,32, r » –1,24ï (11'0,42'0,32) » –1,24ï 1,48 » –0,83 .
In other words, it is necessary to know very firmly that the correlation coefficient can not In absolute value to exceed 1.0. This often avoids gross errors, more precisely - to find and correct the error allowed when calculating.
7.3.3. Spearmen correlation coefficient. As already mentioned, it is possible to apply the BRAVE-Peyson correlation coefficient (R) only in cases where the analyzed frequency distribution factors are close to normal and value options are obtained by measurements necessarily in the relationship scale or in the interval scale, which happens if they are expressed physical units. In other cases, the correlation coefficient of spirit is found ( r.). However, this coefficient can apply in cases where allowed (and preferably ! ) Apply the Correlation Coefficient on Bävse-Pearson. But it should be borne in mind that the procedure for determining the combat-purse coefficient has greater power ("permittingability"), so r.more informative than r.. Even with large n. deviation r. It may be about ± 10%.
Table 7.2 The calculated formula of the coefficient
x i y i r x r y | D R | D R 2 Spearman correlation
13,2 4,75 8,5 3,0 5,5 30,25 r. \u003d 1 -. Rest
13.5 4.70 11.0 2.0 9.0 81.00 We use our example
12.7 5,10 4.5 6.5 2.0 4.00 for calculation r.But build
12.5 5.40 3.0 9.0 6.0 36.00 other table (Table 7.2).
13.0 5.10 6.0 6.5 0.5 0.25 Substitute the values:
13.2 5.00 8.5 4.5 4.0 16.00 R \u003d 1- \u003d
13,1 5,00 7,0 4,5 2,5 6,25 =1– 2538:1320 » 1–1,9 » – 0,9.
13.4 4.65 10.0 1.0 9.0 81.00 We see: r. It turned out to be a bit
12.4 5.60 2.0 11.0 9.0 81.00 more than r.but it is
12.3 5.50 1.0 10.0 9.0 81.00 Chiya is not very large. After all, when
12.7 5.20 4.5 8.0 3.5 12.25 such small n. Values r. and r.
Åd r 2 \u003d 423 is very approximate, little reliable, their actual value can fluctuate widely, therefore the difference r. and r. 0.1 is unnecessarily. Usuallyr.consider as analogr. but only less accurate. Signs for r.and r.shows the focus of communication.
7.3.4. Application and verification of the accuracy of correlation coefficients. Determining the degree of correlation relationships between factors is necessary to manage the development of the factors we need: for this you have to influence other factors that significantly affect it, and you need to know the measure of their effectiveness. You need to know about the relationship of factors to develop or select ready-made tests: the informativeness of the test is determined by the correlation of its results with the manifestations of the feature or properties of interest to us. With no knowledge of correlations, any forms of selection are impossible.
It was noted above that in sports and in general, pedagogical, medical and even economic and sociological practice is of great interest to the definition of deposit , which the one factor contributes to the formation of another. This is due to the fact that in addition to the factors under consideration, target (We are interested in) Factor act, giving every one or another contribution to it, and others.
It is believed that the measure of the contribution of each factor cause can be coefficient of determination D i \u003d R 2 '100%. For example, if R \u003d 0.6, i.e. The relationship between the factors A and B is average, then d \u003d 0.6 2 '100% \u003d 36%. Knowing, in such a way that the contribution of factor A into the formation of factor B is approximately 1 ½ 3, you can, for example, to devote to the targeted development of this factor approximately 1 ½ 3 training time. If the correlation coefficient is R \u003d 0.4, then d \u003d r 2 100% \u003d 16%, or approximately 1 ½ 6 - two more times less, and to devote it to the development of this logic, respectively, only 1 ½ 6 part of the training time.
The values \u200b\u200bof D I for different essential factors give an approximate view of the quantitative relationship of their influences on the target factor that interests us, for the sake of improving which we, in fact, and work on other factors (for example, a long-term jumper running on an increase in the speed of its spinning run, so As it is a factor that gives the most significant contribution to the formation of the result in jumping).
Recall that determining D. It is possible instead r. Put r.Although, of course, the accuracy of the definition is lower.
Based selective (calculated on selective data) The correlation coefficient cannot be concluded that the relationship between the factors under consideration is not possible. In order to make such a conclusion with one degree of reasonableness, use standard criteria for the correlation. Their use implies a linear relationship between factors and normal distribution Frequencies in each of them (meaning not sample, but their general presentation).
You can, for example, apply the T-criteria of Student. His distance
even formula: t P.= –2 , where k is the studied selective correlation coefficient, A n. - Volume of compaable samples. The obtained calculated value of the T-criterion (T p) is compared with the table with a table that chosen by us and the number of freedom of freedom n \u003d n - 2. To get rid of the settlement work, you can use a special table. critical values \u200b\u200bof selective correlation coefficients(see above) corresponding to the presence of a reliable connection between factors (including n. and a.).
Table 7.3.
Boundary values \u200b\u200bof the confidence of selective correlation coefficient
The number of degrees of freedom in determining the correlation coefficients is taken equal to 2 (i.e. n. \u003d 2) specified in Table. 7.3 Values \u200b\u200bhave the lower boundary of the confidence interval true the correlation coefficient is 0, that is, at such values \u200b\u200bit is not impossible to say that the correlation is generally occurred. With the value of the selective correlation coefficient above the specified in the table, it is possible at the appropriate level of significance to believe that the true correlation coefficient is not zero.
But the answer to the question is whether there is a real connection between the factors under consideration, leaves a place for another question: in which interval lies true value correlation coefficient, how can it actually be, with infinitely big n.? This interval for any particular value r. and n. compared factors can be calculated, but it is more convenient to use the system of graphs ( nomogram), where each pair of curves, built for one specified above them n.corresponds to the interval boundaries.
Fig. 7.4. Trust borders of the selective correlation coefficient (A \u003d 0.05). Each curve corresponds to the specified above n..
Turning to the nomogram in fig. 7.4, an interval of values \u200b\u200bof the true correlation coefficient can be determined for the calculated values \u200b\u200bof the selective correlation coefficient at a \u003d 0.05.
7.3.5. Correlation relations.If the pair correlation nelinene, it is impossible to calculate the correlation coefficient, determine correlation relations . Mandatory requirement: Signs must be measured in the scale of relationships or in the scale of intervals. It is possible to calculate the correlation dependence of the factor X. from factor Y.and correlation dependence of the factor Y.from factor X. - They differ. With a small amount n. The samples in question, representing factors, can be used to calculate correlation relations:
correlation ratio H. x ½ y.= ;
correlation ratio H y ½ X.= .
Here and - the average arithmetic samples X and Y, and - intraclass Middle arithmetic. TO is - the arithmetic average of those values \u200b\u200bin the sample of factor x, with which conjugate identical values In the sample of the factor y (for example, if in the Factor x there are values \u200b\u200bof 4, 6, and 5, with which 3 options with the same value 9 are conjugate in the sample of the factor y, then \u003d (4 + 6 + 5) ½ 3 \u003d 5). Accordingly, the arithmetic average of those values \u200b\u200bin the sample of the factor Y, with which the same values \u200b\u200bare conjugated in the sample of the Factor X. Let us give an example and carry out the calculation:
X: 75 77 78 76 80 79 83 82 ; Y: 42 42 43 43 43 44 44 45 .
Table 7.4.
Calculated table
| X I. | Y I. | X Y. | x i - x | (x i - x) 2 | x I - x y. | (x I.– X Y.) 2 |
| –4 | –1 | |||||
| –2 | ||||||
| –3 | –2 | |||||
| –1 | ||||||
| –3 | ||||||
| x \u003d 79. | Y \u003d 43. | S \u003d 76. | S \u003d 28. |
Consequently, H. Y ½ X.\u003d "0.63.
7.3.6. Private and multiple correlation coefficients.To estimate the relationship between 2 factors, calculating the correlation coefficients, we, as it were, we assume that no other factors for this dependence have no effects. In reality, the situation is wrong. So, the dependence between weight and growth is very significantly influenced by calorieness of nutrition, the magnitude of systematic physical exertion, heredity, etc. When needed when evaluating communication between 2 factors considerable influence other factors and at the same time how to isolate from them considering them unchanged, calculate private (otherwise - partial ) Correlation coefficients.
Example: you need to evaluate the paired dependences between the 3 substantially active factors X, Y and Z. Denote r. XY (Z) Private (partial) correlation coefficient between Factors X and Y (at the same time, we consider the value of the factor z unchanged), r. ZX (Y) is a private correlation coefficient between factors Z and X (with the consistent value of the factor y), r. YZ (X) is a private correlation coefficient between Y and Z factors (with the consistent value of the Factor X). Using the calculated simple pair (BRAVE-purson) correlation coefficients r. XY r. Xz I. r. YZ, M.
it is possible to calculate private (partial) correlation coefficients by formulas:
r xy - r. Xz ' r. Yz. r. Xz - r. Xy ' r. ZY. r. ZY -R ZX ' r. Yz.
r. Xy (z) \u003d; r. Xz (y) \u003d; r. Zy (x) \u003d
Ö (1- r. 2 xz) (1- r. 2 yz) Ö (1- r. 2 XY) (1- r. 2 zy) Ö (1- r. 2 zx) (1- r. 2 yx)
And private correlation coefficients can take values \u200b\u200bfrom -1 to +1. Erecting them in a square, get the appropriate private determination coefficients , also referred to as private measures of certainty (multiplying by 100, express in %%). Private correlation coefficients are more or less different from simple (complete) paired coefficients, which depends on the strength of the influence on them of the 3rd factor (as if unchanged). Zero hypothesis (H 0), that is, a hypothesis about the absence of communication (dependence) between X and Y factors is checked (with a total of signs k.) Calculation of the T-criterion by the formula: t. P \u003d. r. XY (Z) '( n.-K) 1. ½ 2 '(1- r. 2 XY (Z)) -1 ½ 2 .
If a t. R< t. a n, the hypothesis is accepted (we believe that there is no dependence), if t. P ³ t. A n - the hypothesis is refuted, that is, it is believed that the dependence really takes place. t. a n is taken on the table t.-Criteria Student, and k. - Number of accounted factors (in our example 3), the number of degrees of freedom n. \u003d N - 3. Other private correlation coefficients are checked similarly (in the formula instead r. XY (z) are substituted accordingly r. Xz (y) or r. Zy (x)).
Table 7.5.
Initial data
| X (years) | Y (times) | Z (times) | X (years) | Y (times) | Z (times) | |||||||||||||||||
| Sign 1 Sign 2 | Intravert | Extraverability |
| Sport games | but | b. |
| Gymnastics | from | d. |
Obviously, only frequencies of distributions can be numbers here at our disposal. In this case, calculate coefficient of the Association (other name " coefficient of conjugacy "). Consider the simplest case: the relationship between two pairs of signs, with the calculated coefficient of conjugacy call tetrachoric (See Table.).
Table 7.7.
| a \u003d 20. | b \u003d 15. | a. + b. = 35 |
| c \u003d 15. | d \u003d 5. | c. + d. = 20 |
| a. + c. = 35 | b. + d. = 20 | n. = 55 |
Calculations produce by the formula:
aD - BC 100 - 225 -123
Calculation of the coefficients of the association (pairing coefficients) with a larger number of features is associated with calculations on a similar matrix of the appropriate order.
Correlation coefficient - This is a magnitude that can vary from +1 to -1. In the case of a complete positive correlation, this coefficient is plus 1 (they suggest that with an increase in the value of one variable, the value of another variable increases), and with a complete negative - minus 1 (indicate a feedback, i.e. with an increase in the values \u200b\u200bof one variable, The different values \u200b\u200bare reduced).
 PR1.:
PR1.:
The graph of the dependence of shyness and dipresis. As you can see, the points (subjects) are not chaotic, but built around one line, and looking at this line we can say that the higher the person is expressed in the person, the more depressiveness, i.e., these phenomena are interconnected.

 PR2.: Schedule for shyness and sociability. We see that with an increase in shyness, sociability decreases. Their correlation coefficient is -0.43. Thus, the correlation coefficient greater from 0 to 1 speaks of direct-proportional communication (the greater ... the more ...), and the coefficient from -1 to 0 about the disgraceful (the more ... the less ...)
PR2.: Schedule for shyness and sociability. We see that with an increase in shyness, sociability decreases. Their correlation coefficient is -0.43. Thus, the correlation coefficient greater from 0 to 1 speaks of direct-proportional communication (the greater ... the more ...), and the coefficient from -1 to 0 about the disgraceful (the more ... the less ...)
 If the correlation coefficient is 0, both variables are completely independent of each other.
If the correlation coefficient is 0, both variables are completely independent of each other.
Correlation - This is a connection where the exposure of individual factors is manifested only as a tendency (on average) with mass observation of actual data. Examples of correlation dependences can be dependencies between the size of the bank's assets and the amount of the Bank's profits, the growth of labor productivity and experience of employees.
Two systems of classification of correlation ties in their strength are used: general and private.
General classification of correlations: 1) Strong, or close with the correlation coefficient R\u003e 0.70; 2) average at 0.500.70, and not just a correlation of a high level of significance.The following table wrote the names of the correlation coefficients for various types of scales.
| Dichotomic scale (1/0) | Rank (ordinal) scale | ||
| Dichotomic scale (1/0) | The coefficient of the Pearson Association, the Four-Board Pearson Coefficient. | Beiserial correlation | |
| Rank (ordinal) scale | Rank biserial correlation. | Range coefficient of correlation of spirit or kendalla. | |
| Interval and absolute scale | Beiserial correlation | The values \u200b\u200bof the interval scale are translated into ranks and is used rank coefficient | Pearson correlation coefficient (linear correlation coefficient) |
For r.=0 linear correlation is missing. At the same time, group average variables coincide with their shared averages, and the regression lines are parallel to the coordinate axes.
Equality r.=0 it speaks only about the absence of a linear correlation dependence (non-corrosion of variables), but not at all about the absence of correlation, and even more so, statistical dependence.
Sometimes the conclusion about the absence of correlation is more important than the presence of a strong correlation. The zero correlation of two variables may indicate that there is no effect of one variable to another, provided that we trust the measurement results.
In SPSS: 11.3.2 Correlation coefficients
Until now, we figured out only the fact of the existence of a statistical dependence between the two signs. Next, we will try to find out which conclusions can be done about the strength or weakness of this dependence, as well as about its form and orientation. The criteria for a quantitative assessment of the relationship between variables are called correlation coefficients or connectedness measures. Two variables correlate with each other positively, if there is a direct, unidirectional ratio between them. With a unidirectional ratio, small values \u200b\u200bof one variable correspond to small values \u200b\u200bof another variable, large values \u200b\u200bare large. Two variables correlate with each other negatively, if there is a reverse, multidirectional ratio between them. With a multidirectional ratio, small values \u200b\u200bof one variable correspond to the large values \u200b\u200bof another variable and vice versa. The values \u200b\u200bof the correlation coefficients are always lying in the range from -1 to +1.
The coefficient of correlation between the variables belonging to the ordinal scale is used by the coefficient of the coefficient, and for variables belonging to the interval - the Pearson correlation coefficient (the moment of works). It should be noted that each dichotomous variable, that is, a variable belonging to the nominal scale and having two categories can be considered as ordinal.
To begin with, we will check if the correlation between the SEX and PSYCHE variables from the studium.sav file. At the same time, we take into account that the dichotomic variable of Sex can be considered ordinary. Follow these steps:
· Select DESCRIPTIVE STATISTICS (descriptive statistics) commands in the Analyze command menu ... (conjugacy tables)
· Transfer the SEX variable to the string list, and the PSYCHE variable is in the column list.
· Click on the Statistics ... (statistics) button. In the Crosstabs: Statistics dialog, select the Correlations checkbox (correlation). Confirm the contact with the Continue button.
· In the Crosstabs dialog, refuse to output the tables by checking the Supress Tables check box. Click on the OK button.
The coefficients of the correlation coefficients of the spirote and Pearson will be calculated, and their significance is checked:
/ SPSS 10.
Task number 10 Correlation analysis
Concept of correlation
Correlation or correlation coefficient is a statistical indicator probabilisticcommunication between two variables measured by quantitative scales. In contrast to the functional connection, in which each value of one variable corresponds to strictly definedthe value of another variable, probabilistic communicationit is characterized by the fact that each value of one variable corresponds to many valuesanother variable, an example of probabilistic communication is the relationship between the growth and weight of people. It is clear that the same height can be in people of different weight and vice versa.
The correlation is the value concluded from -1 to + 1, and is indicated by the letter R. Moreover, if the value is closer to 1, this means the presence of a strong connection, and if closer to 0, then weak. The correlation value of less than 0.2 is considered as a weak correlation, over 0.5 - high. If the correlation coefficient is negative, this means the presence of feedback: the higher the value of one variable, the lower the different value.
Depending on the value of the coefficient values, it is possible to allocate various types of correlation:
Strict positive correlationdetermined by the value ofr \u003d 1. The term "strict" means that the value of one variable is uniquely determined by the values \u200b\u200bof another variable, and the term " positive "- that with an increase in the values \u200b\u200bof one variable, the value of another variable is also increasing.
Strict correlation is mathematical abstraction and practically does not occur in real studies.
Positive correlation Corresponds to the values \u200b\u200bof 0.
Lack of correlationdetermined by the value ofr \u003d 0. The correlation zero coefficient suggests that the values \u200b\u200bof the variables are not related to each other.
Lack of correlation H. o. : 0 r. xY. =0 formulated as reflection null Hypothesis in correlation analysis.
Negative correlation: -1
Strict negative correlationdetermined by the value ofr \u003d -1. It also, as well as a strict positive correlation, is abstraction and does not find an expression in practical research.
Table 1
Types of correlation and their definitions
The method for calculating the correlation coefficient depends on the type of scale on which the values \u200b\u200bof the variable are measured.
Correlation coefficient r.Pearsonit is the main and can be used for variables with nominal and partially ordered, interval scales, the distribution of values \u200b\u200bby which corresponds to normal (correlation of the moments of the work). The Pearson correlation coefficient gives fairly accurate results and in cases of abnormal distributions.
For distributions that are not normal, it is preferable to use the coefficients of the ranking correlation of spirmen and Kendalla. Range they are because the program is pre-ranking correlated variables.
The correlation of the RPRMAN programSPSSS provides as follows: First, variables are transferred to ranks, and then the formulason is used to rank.
At the heart of the correlation proposed by M. Kendalla, there is an idea that the direction of communication can be judged, in pairwise comparing the subjects among themselves. If a pair of tested changes in x coincide in the direction with a change in paying, this indicates a positive connection. If it does not coincide - then a negative connection. This coefficient is used mainly by psychologists working with small samples. Since sociologists work with large data arrays, it is difficult to identify the difference in the relative frequencies and inversions of all pairs of subjects in the sample. The most common is the coefficient. Pearson.
Since the RPirson correlation coefficient is main and can be used (with a certain error depending on the type of scale and level of abnormality in the distribution) for all variables measured by quantitative scales, consider examples of its use and compare the results obtained with measurement results according to other correlation coefficients.
Formula for calculating the coefficient r.- Pearson:
r xy \u003d σ (xi-xcp) ∙ (yi-ycr) / (n - 1) ∙ Σ x ∙ Σ y ∙
Where: xi, yi- the values \u200b\u200bof two variables;
XSR, YCR - average values \u200b\u200bof two variables;
σ x, σ y - standard deviations,
N- Number of observations.
Paired correlations
For example, we would like to find out how the answers between the various types of traditional values \u200b\u200brelate in the idea of \u200b\u200bstudents about the ideal place of work (variables: A9.1, A9.3, A9.5, A9.7), and then the ratio of liberal values \u200b\u200b(A9 .2, a9.4. A9.6, A9.8). These variables are measured by 5 - membered ordered scales.
We use the procedure: "Analysis", "Correlation", "Paired". Default Coeff. Pearson is set in the dialog box. We use coefficients. Pearson
Test variables are transferred to the selection window: A9.1, A9.3, A9.5, A9.7
By pressing ok, we get the calculation:
Correlation
|
a9.1.T. How important is it enough time for family and personal life? |
Pearson correlation |
||||
|
ZNch. (2 sides) |
|||||
|
a9.3.t. How important is not to be afraid of losing your work? |
Pearson correlation |
||||
|
ZNch. (2 sides) |
|||||
|
a9.5.T. How important is it to have such a boss who will advise with you, accepting this or that decision? |
Pearson correlation |
||||
|
ZNch. (2 sides) |
|||||
|
a9.7.T. How important is it to work in a coherent team, feel part of it? |
Pearson correlation |
||||
|
ZNch. (2 sides) |
|||||
** Correlation is meaningful at the level of 0.01 (2 sides.).
Table of quantitative values \u200b\u200bof the constructed correlation matrix
Private correlations:
To begin with, we construct a pair correlation between the two variables specified:
|
Correlation |
|||
|
c8. Feel intimacy with those who live near you, neighbors |
Pearson correlation |
||
|
ZNch. (2 sides) |
|||
|
c12. Feel intimacy with her family |
Pearson correlation |
||
|
ZNch. (2 sides) |
|||
|
**. The correlation is meaningful at the level of 0.01 (2-sides.). |
|||
Then use the procedure for building a private correlation: "Analysis", "Correlation", "Private".
Suppose that the value "It is important to determine and change the order of your work" in relation to the specified variables will be the decisive factor, under the influence of which the previously identified connection will disappear, or will be unfounded.
|
Correlation |
||||
|
Excluded variables |
c8. Feel intimacy with those who live near you, neighbors |
c12. Feel intimacy with her family |
||
|
c16. Feel intimacy with people who have the same wealth as you |
c8. Feel intimacy with those who live near you, neighbors |
Correlation |
||
|
Significance (2nd.) |
||||
|
c12. Feel intimacy with her family |
Correlation |
|||
|
Significance (2nd.) |
||||
As can be seen from the table under the influence of the control variable, the connection has slightly decreased: from 0, 120 to 0, 102. However, this slightly decrease does not allow to assert that the wound is a reflection of false correlation, because It remains high enough and allows with a zero error to refute the zero hypothesis.
Correlation coefficient
The most accurate way to determine the crosses and the nature of the correlation is to find the correlation coefficient. The correlation coefficient is the number defined by the formula:


where R hu is the correlation coefficient;
x i -thodics of the first feature;
at the i-apposition of the second feature;
The average arithmetic values \u200b\u200bof the first sign
The average arithmetic values \u200b\u200bof the second feature
To use the formula (32), we construct a table that will provide the necessary sequence in the preparation of numbers to find the numerator and the denominator of the correlation coefficient.
As can be seen from formula (32), the sequence of actions is this: we find the average arithmetic of both signs x and y, we find the difference between the values \u200b\u200bof the feature and its average (x i -) and і -), then find their work (x і) ( I І -) - the sum of the priest gives the correlation coefficient numerator. To find his denominator, it follows the difference (X I -) and (at І -) to build a square, find them amounts and extract the square root from their work.
So for example 31, the correlation coefficient in accordance with formula (32) can be represented as follows (Table 50).
The resulting number of correlation coefficient makes it possible to establish the presence, tightness and nature of communication.
1. If the correlation coefficient is zero, there is no connection between the signs.
2. If the correlation coefficient is equal to one, the relationship between the signs is so large, which turns into a functional one.
3. The absolute value of the correlation coefficient does not go beyond the range from zero to one:
This makes it possible to navigate the tightness of the connection: the value of the coefficient closer to zero, the connection is weaker, and the closer to one, the connection is closer.
4. The "Plus" correlation coefficient sign means a direct correlation, a "minus" sign.
Table 50
| x і. | І. | (x i -) | (y -) | (x і -) (y -) | (x і -) 2 | (y і -) 2 |
| 14,00 | 12,10 | -1,70 | -2,30 | +3,91 | 2,89 | 5,29 |
| 14,20 | 13,80 | -1,50 | -0,60 | +0,90 | 2,25 | 0,36 |
| 14,90 | 14,20 | -0,80 | -0,20 | +0,16 | 0,64 | 0,04 |
| 15,40 | 13,00 | -0,30 | -1,40 | +0,42 | 0,09 | 1,96 |
| 16,00 | 14,60 | +0,30 | +0,20 | +0,06 | 0,09 | 0,04 |
| 17,20 | 15,90 | +1,50 | +2,25 | 2,25 | ||
| 18,10 | 17,40 | +2,40 | +2,00 | +4,80 | 5,76 | 4,00 |
| 109,80 | 101,00 | 12,50 | 13,97 | 13,94 |


Thus, calculated in Example 31, the correlation coefficient R xy \u003d +0.9. Allows you to make such conclusions: there is a correlation bond between the magnitude of the muscular power of the right and left brushes in the studied schoolchildren (the coefficient R xy \u003d + 0.9 is different from zero), the connection is very close (the coefficient R xy \u003d + 0.9 is close to one), correlation is straightforward (R Coefficient XY \u003d +0.9 positive), i.e., with an increase in the muscular strength of one of the brushes, the strength of another brush increases.
When calculating the correlation coefficient and using its properties, it should be noted that the conclusions give correct results in the case when the signs are distributed normally and when the relationship between the large number of values \u200b\u200bof both signs is considered.
In the considered example 31, only 7 values \u200b\u200bof both signs were analyzed, which, of course, is not enough for such studies. We remind here again that examples in this book in general and in this chapter in particular, are the nature of the methods of methods, and not a detailed presentation of any scientific experiments. As a result, a small number of signs of signs is considered, measuring is rounded - all this is done in order for bulky calculations to not dow the idea of \u200b\u200bthe method.
Special attention should be paid to the essence of the relationship under consideration. The correlation coefficient cannot lead to the correct results of the study, if the analysis of the relationship between the signs is carried out formally. Let's return again for example 31. Both considered features were the meaning of muscular power of the right and left brushes. Imagine that under the sign of XI in example 31 (14.0; 14.2; 14.9 ... ... 18.1) we understand the length of accidentally caught fish in centimeters, and under the sign of І (12,1 ; 13.8; 14.2 ... ... 17.4) -At devices in the laboratory in kilograms. Formally, using the computing apparatus to find the correlation coefficient and obtaining in this case also R xy \u003d + 0\u003e 9, we had to conclude that there is a close relationship between fish and the weight of the instruments. The meaninglessness of this conclusion is obvious.
To avoid a formal approach to using the correlation coefficient, it follows by any other method - mathematical, logical, experimental, theoretical - to identify the possibility of the existence of a correlation between the signs, that is, to detect the organic unity of the signs. Only after that you can proceed to the use of correlation analysis and set the value and nature of the relationship.
In mathematical statistics there is still a concept multiple correlation - Relationships between three and more signs. In these cases, use the multiple correlation coefficient consisting of paired correlation coefficients described above.
For example, the correlation coefficient of three signs-x І, y і, z і - there:
where R xyz is a multiple correlation-cylinder, expressing as a sign X I depends on the signs of І and Z I;
r xy-cell correlation between the signs X i and Y i;
r xz -Coeffer correlation between signs XI and Zi;
r yz. - correlation coefficient between signs Y i, Z I
Correlation analysis is:
Correlation analysisCorrelation - the statistical relationship between two or several random variables (or values \u200b\u200bthat can be considered as such with some permissible accuracy). At the same time, changes in one or more of these values \u200b\u200blead to a systematic change in other or other values. The mathematical measure of the correlation of two random variables is the correlation coefficient.
The correlation can be positive and negative (there is also a situation of lack of statistical relationships - for example, for independent random variables). Negative correlation - Correlation at which an increase in one variable is associated with a decrease in another variable, while the correlation coefficient is negative. Positive correlation - Correlation at which an increase in one variable is associated with an increase in another variable, while the correlation coefficient is positive.
Autocorrelation - The statistical relationship between random values \u200b\u200bfrom one row, but to be taken with a shift, for example, for a random process - with a shift in time.
The method of processing statistical data consisting in the study of coefficients (correlation) between variables, is called correlation analysis.
Correlation coefficient
Correlation coefficient or farmer correlation coefficient In probability and statistics theory, this is an indicator of the nature of the change in two random variables. The correlation coefficient is indicated by the Latin letter R and can take values \u200b\u200bbetween -1 and +1. If the value of the module is closer to 1, then this means the presence of a strong bond (with a correlation coefficient, the unit is talking about the functional connection), and if closer to 0, then weak.
Pearson correlation coefficient
For metric values, the Pearson correlation coefficient is applied, the exact formula of which was introduced by Francis Galton:
Let be X.,Y. - Two random variables defined on one probabilistic space. Then their correlation coefficient is set by the formula:

 ,
,
where cov means covariance, and D is a dispersion, or that the same thing
,where the symbol refers to a mathematical expectation.
You can use a rectangular coordinate system with axes that correspond to both variables. Each pair of values \u200b\u200bis marked using a specific symbol. Such a chart is called a "scattering diagram".
The method of calculating the correlation coefficient depends on the type of scale to which variables relate. Thus, to measure variables with interval and quantitative scales, it is necessary to use the Pearson correlation coefficient (correlation of the moments of works). If at least one of two variables has a sequence scale, or is not normally distributed, it is necessary to use the rank correlation of the alcoholic or τ (Tau) kendale. In the case when one of two variables is dichotomous, a point double-row correlation is used, and if both variables are dichotomous: four-way correlation. Calculation of the correlation coefficient between two non-fractional variables is not deprived of meaning only then, the link is bond between them of linear (unidirectional).
Correlation coefficient Kendella
Used to measure mutual disorder.
Spearman correlation coefficient
Properties of the correlation coefficient
- The inequality of Cauchy - Bunyakovsky:
Correlation analysis
Correlation analysis - method of processing statistical data consisting in the study of coefficients ( correlation) Between variables. In this case, the correlation coefficients are compared between one pair or a variety of pairs of features to establish statistical relationships between them.
purpose correlation analysis - Provide some information about one variable using another variable. In cases where it is possible to achieve the goal, it is said that variables correlate. In the most general form, the adoption of the hypothesis on the presence of correlation means that the change in the value of the variable A will occur simultaneously with a proportional change in the value of B: if both variables grow correlation positiveif one variable grows, and the second decreases, negative correlation.
The correlation reflects only a linear dependence of quantities, but does not reflect their functional connectedness. For example, if calculating the correlation coefficient between values A. = s.i.n.(x.) I. B. = c.o.s.(x.), then it will be close to zero, i.e., the dependence between the values \u200b\u200bis absent. Meanwhile, the values \u200b\u200ba and b are obviously associated functionally by law s.i.n.2(x.) + c.o.s.2(x.) = 1.
Restrictions of correlation analysis

 Couples (x, y) distribution graphs with appropriate X and Y correlation coefficients for each of them. Note that the correlation coefficient reflects the linear dependence (top line), but does not describe the dependence curve (average line), and is not at all suitable for describing complex, nonlinear dependencies (lower line).
Couples (x, y) distribution graphs with appropriate X and Y correlation coefficients for each of them. Note that the correlation coefficient reflects the linear dependence (top line), but does not describe the dependence curve (average line), and is not at all suitable for describing complex, nonlinear dependencies (lower line). - Application is possible in the case of a sufficient number of cases for study: for a specific type of correlation coefficient ranges from 25 to 100 surveillance pairs.
- The second limitation follows from the hypothesis of the correlation analysis in which it is laid linear dependence of variables. In many cases, when it is reliably known that the dependence exists, the correlation analysis may not give results simply due to the fact that the relationship is nonlinear (expressed, for example, in the form of a parabola).
- By itself, the fact of correlation dependences does not provide grounds to argue which of the variables precedes or is the cause of changes, or that the variables are generally causally connected with each other, for example, due to the actions of the third factor.
Application area
This method of processing statistical data is very popular in the economy and social sciences (in particular in psychology and sociology), although the scope of the correlation coefficients is extensive: quality control of industrial products, metal studies, agrochemistry, hydrobiology, biometrics and others.
The popularity of the method is due to two moments: the correlation coefficients are relatively simple in counting, their use does not require special mathematical training. In combination with the simplicity of interpretation, the simplicity of the coefficient has led to its widespread in the scope of analysis of statistical data.
False correlation
Often tempting simplicity of correlation research pushes the researcher to make false intuitive conclusions about the presence of a causal relationship between couples of signs, while the correlation coefficients establish only statistical relationships.
In the modern quantitative methodology of social sciences, in fact, there was a refusal to attempt to establish causal relations between the observed variables of empirical methods. Therefore, when researchers in social sciences speak of the establishment of interrelations between the variables studied, it means either a general-relevant assumption or statistical dependence.
see also
- Autocorrelation function
- Corresponduring function
- Covariator
- Coefficient of determination
- Regression analysis
Wikimedia Foundation. 2010.
Correlation coefficient - This is a magnitude that can vary from +1 to -1. In the case of a complete positive correlation, this coefficient is plus 1 (they suggest that with an increase in the value of one variable, the value of another variable increases), and with a complete negative - minus 1 (indicate a feedback, i.e. with an increase in the values \u200b\u200bof one variable, The different values \u200b\u200bare reduced).
PR1.:
The graph of the dependence of shyness and dipresis. As you can see, the points (subjects) are not chaotic, but built around one line, and looking at this line we can say that the higher the person is expressed in the person, the more depressiveness, i.e., these phenomena are interconnected.
PR2.: Schedule for shyness and sociability. We see that with an increase in shyness, sociability decreases. Their correlation coefficient is -0.43. Thus, the correlation coefficient greater from 0 to 1 speaks of direct-proportional communication (the greater ... the more ...), and the coefficient from -1 to 0 about the disgraceful (the more ... the less ...)
If the correlation coefficient is 0, both variables are completely independent of each other.
Correlation - This is a connection where the exposure of individual factors is manifested only as a tendency (on average) with mass observation of actual data. Examples of correlation dependences can be dependencies between the size of the bank's assets and the amount of the Bank's profits, the growth of labor productivity and experience of employees.
Two systems of classification of correlation ties in their strength are used: general and private.
General classification of correlations: 1) Strong, or close with the correlation coefficient R\u003e 0.70; 2) average at 0.500.70, and not just a correlation of a high level of significance.The following table wrote the names of the correlation coefficients for various types of scales.
| Dichotomic scale (1/0) | Rank (ordinal) scale | ||
| Dichotomic scale (1/0) | The coefficient of the Pearson Association, the Four-Board Pearson Coefficient. | Beiserial correlation | |
| Rank (ordinal) scale | Rank biserial correlation. | Range coefficient of correlation of spirit or kendalla. | |
| Interval and absolute scale | Beiserial correlation | The values \u200b\u200bof the interval scale are translated into ranks and is used rank coefficient | Pearson correlation coefficient (linear correlation coefficient) |
For r.=0 linear correlation is missing. At the same time, group average variables coincide with their shared averages, and the regression lines are parallel to the coordinate axes.
Equality r.=0 it speaks only about the absence of a linear correlation dependence (non-corrosion of variables), but not at all about the absence of correlation, and even more so, statistical dependence.
Sometimes the conclusion about the absence of correlation is more important than the presence of a strong correlation. The zero correlation of two variables may indicate that there is no effect of one variable to another, provided that we trust the measurement results.
In SPSS: 11.3.2 Correlation coefficients
Until now, we figured out only the fact of the existence of a statistical dependence between the two signs. Next, we will try to find out which conclusions can be done about the strength or weakness of this dependence, as well as about its form and orientation. The criteria for a quantitative assessment of the relationship between variables are called correlation coefficients or connectedness measures. Two variables correlate with each other positively, if there is a direct, unidirectional ratio between them. With a unidirectional ratio, small values \u200b\u200bof one variable correspond to small values \u200b\u200bof another variable, large values \u200b\u200bare large. Two variables correlate with each other negatively, if there is a reverse, multidirectional ratio between them. With a multidirectional ratio, small values \u200b\u200bof one variable correspond to the large values \u200b\u200bof another variable and vice versa. The values \u200b\u200bof the correlation coefficients are always lying in the range from -1 to +1.
The coefficient of correlation between the variables belonging to the ordinal scale is used by the coefficient of the coefficient, and for variables belonging to the interval - the Pearson correlation coefficient (the moment of works). It should be noted that each dichotomous variable, that is, a variable belonging to the nominal scale and having two categories can be considered as ordinal.
To begin with, we will check if the correlation between the SEX and PSYCHE variables from the studium.sav file. At the same time, we take into account that the dichotomic variable of Sex can be considered ordinary. Follow these steps:
· Select DESCRIPTIVE STATISTICS (descriptive statistics) commands in the Analyze command menu ... (conjugacy tables)
· Transfer the SEX variable to the string list, and the PSYCHE variable is in the column list.
· Click on the Statistics ... (statistics) button. In the Crosstabs: Statistics dialog, select the Correlations checkbox (correlation). Confirm the contact with the Continue button.
· In the Crosstabs dialog, refuse to output the tables by checking the Supress Tables check box. Click on the OK button.
The coefficients of the correlation coefficients of the spirote and Pearson will be calculated, and their significance is checked:
/ Theory. Correlation coefficient
Correlation coefficient - Two-dimensional descriptive statistics, quantitative measure of the relationship (joint variability) of two variables.
To date, a great many different correlation coefficients have been developed. However, the most important communication measures - Pearson, Spearman and Kendalla . Their overall feature is that they reflect the relationship of two signs , measured in a quantitative scale - rank or metric .
Generally speaking, any empirical study is focused on studying the relationships of two or more variables. .
If the change in one variable per unit always leads to a change in another variable on the same value, the function is linear (the schedule represents a straight line); any other connection - nonlinear . If an increase in one variable is associated with an increase in the other, then communication - positive ( straight ) ; If an increase in one variable is associated with a decrease in the other, then communication - negative ( inverse ) . If the direction of change of one variable does not change with an increase in (descending) another variable, then such a function - monotonna ; otherwise the function is called nonmonotonic .
Functional relations are idealizations. Their feature is that one value of one variable corresponds to a strictly defined value of another variable. For example, this is the relationship of two physical variables - weights and body lengths (linear positive). However, even in physical experiments, the empirical relationship will differ from the functional relationship due to unaccounted or unknown causes: oscillations of the composition of the material, measurement errors, etc.
When studying the relationship of signs from the field of view of the researcher, many possible causes of variability of these signs inevitably falls. The result is that even existing in reality, the functional connection between variables acts empirically as a probabilistic (stochastic): the same value of one variable corresponds to the distribution of various values \u200b\u200bof another variable (and vice versa).
The simplest example is the ratio of growth and weight of people. The empirical results of the study of these two signs will show, of course, their positive relationship. But it is easy to guess that it will differ from a strict, linear, positive - ideal mathematical function, even with all the tricks of the researcher on the accounting of harmony or completeness of the subjects. It is unlikely that on this basis someone will come to mind to deny the fact of the presence of a strict functional connection between the length and weight of the body.
So, the functional relationship of phenomena empirically can only be detected as a probabilistic connection of the respective signs.
A visual idea of \u200b\u200bthe character of a probabilistic communication gives a dispersion diagram - a graph, the axis of which corresponds to the values \u200b\u200bof two variables, and each subject is a point. Correlation coefficients are used as a numerical characteristic of probability communication.
You can enter three gradations of the correlation values \u200b\u200bfor communication force:
r.< 0,3 - слабая связь (менее 10% от общей доли дисперсии);
0,3 < r < 0,7 - умеренная связь (от 10 до 50% от общей доли дисперсии);
r\u003e 0.7 - strong bond (50% or more of the total fraction of dispersion).
Private correlation
It often happens that two variables correlate with each other only due to the fact that both of them are changing under the influence of some third variable. That is, in fact, the relationship between the corresponding properties of these two variables is absent, but manifests itself in a statistical relationship, or correlation, under the influence of the total cause of the third variable).
Thus, if the correlation between two variables decreases, with a fixed third random value, this means that their interdependence occurs in part through the impact of this third variable. If the private correlation is zero or very small, we can conclude that their interdependence is entirely due to its own impact and is not related to the third variable.
Also, if the private correlation is greater than the initial correlation between two variables, we can conclude that other variables weakened the connection, or "hidden" the correlation.
In addition, it is necessary to remember that correlation is not causality . Based on this, we have no right to designerly talk about the presence of a causal connection: some completely different from the analysis considered in the analysis can be the source of this correlation. Both with ordinary correlation, and under private correlations, the assumption of causality should always have their own non-vital foundations.
Pearson correlation coefficient
r- Pearson used to study the relationship of two metric variables , measured on the same sample . There are many situations in which its use is appropriate. Does intelligence affect the academic performance at the university's senior courses? Is the amount of wages of an employee with his benevolence to colleagues? Does the schoolboy's mood affect the success of solving a complex arithmetic task? For an answer to such questions, the researcher must measure the two indicators of interest to each member of the sample.
The value of the correlation coefficient does not affect what signs are presented in which measurement units. Consequently, any linear character conversion (multiplication to the constant, the addition of the constant) do not change the values \u200b\u200bof the correlation coefficient. The exception is the multiplication of one of the signs on the negative constant: the correlation coefficient changes its sign to the opposite.
Pearson correlation there is a linear communication between two variables . It allows you to determine , how proportional to the variability of two variables . If the variables are proportional to each other, then graphically the connection between them can be represented as a straight line with a positive (direct proportion) or negative (reverse proportion) by the slope.
In practice, the relationship between two variables, if it is, is probabilistic and graphically looks like a cloud dispersion of an ellipsoid form. This ellipsoid, however, can be submitted (approximate) in the form of a straight line, or regression lines. Regression line - This is a straight line constructed by the least squares: the sum of the squares of the distances (calculated along the Y axis) from each point of the scattering schedule to the straight is minimal.
Of particular importance for estimating the prediction accuracy is the dispersion of estimates of the dependent variable. In fact, the dispersion of estimates of the dependent variable y is the part of its complete dispersion, which is due to the influence of an independent variable X. In other words, the ratio of the dispersion of estimates of the dependent variable to its true dispersion is equal to the square of the correlation coefficient.
The square of the correlation coefficient of dependent and independent variables is a fraction of the dispersion of the dependent variable due to the influence of an independent variable, and is called coefficient of determination . The determination coefficient, thus, shows the extent to which the variability of one variable is due to (determined) with the influence of another variable.
The determination coefficient has an important advantage compared to the correlation coefficient. The correlation is not a linear communication function between two variables. Therefore, the average arithmetic correlation coefficients for multiple samples does not coincide with the correlation calculated immediately for all subjects from these samples (i.e., the correlation coefficient is not additive). On the contrary, the determination coefficient reflects the connection linearly and therefore is additive: its averaging is allowed for several samples.
Additional information on the power of communication gives the value of the correlation coefficient in the square - the determination coefficient: this is part of the dispersion of one variable, which can be explained by the effect of another variable. In contrast to the correlation coefficient, the determination coefficient is linearly increasing with an increase in communication force.
Correlation coefficients of spirit and τ-kendalla (rank correlations). If both variables are between which the connection is studied, are presented in a procedure scale, or one of them - in order, and the other - in the metric, then the rank correlation coefficients are applied: Spearman or τ. - Kendella . And T. , and another coefficient requires its use of pre-ranking of both variables. .
Spearman's rank correlation coefficient - this is non-parametric method , which is used for the purpose of statistical study of communication between phenomena . In this case, the actual degree of parallelism is determined between the two quantitative rows of the studied characteristics and is given the assessment of the definition of the established connection using a quantitatively pronounced coefficient.
If the members of the group members were ranked first along the X variable, then according to the variable Y, then the correlation between the X and Y variables can be obtained, simply calculating the Pearson coefficient for two rows of ranks. Subject to the absence of bonds in ranks (that is, the lack of repeated ranks) on the other variable, the formula for Pearson can be significantly simplified in computational terms and transformed into a formula known as Spearmene .
The power coefficient of the river correlation of the spirit is somewhat inferior to the power of the parametric correlation coefficient.
The coefficient of rank correlation is advisable to apply if there is a small number of observations . This method can be used not only for quantitatively pronounced data. , but also in cases , when registered values \u200b\u200bare determined by descriptive signs of different intensity .
The coefficient of rank correlation of the alcoholic with a large number of identical ranks on one or both of the compaable variables gives coarse values. Ideally, both correlated rows must be two sequences of inappropriate values.
Alternative to Correlation Spearman for Rights Represents Correlation τ-kendalla . At the heart of the correlation proposed by M. Kendalle, lies the idea that the direction of communication can be judged, in a pairwise comparing the tests among themselves: if a pair of tests under X coincides in the direction with a change in Y, this indicates a positive connection if Does not coincide - then on a negative connection.
Correlation coefficients were specially designed for numerical determination of the strength and direction of communication between the two properties measured in numeric scales (metric or rank).
As already mentioned the maximum strength of the communication corresponds to the correlation values \u200b\u200b+1 (strict direct or directly proportional communication) and -1 (strict reverse or back proportional communication), the absence of communication corresponds to the correlation equal to zero.
Additional information on the power of communication gives the value of the determination coefficient: this is part of the dispersion of one variable, which can be explained by the effect of another variable.
Topic 12 Correlation Analysis
Functional dependence and correlation. More hippocrates in the VI century. BC e. Drew attention to the presence of communication between the physique and temperament of people, between the structure of the body and the predisposition to one or another diseases. Certain types of this relationship are also identified in the animal and the plant world. So, there is a relationship between the physique and productivity in farm animals; The relationship between the quality of seeds and the yield of cultivated plants, etc. As for such dependencies in ecology, there are the dependencies between the content of heavy metals in the soil and the snow cover from their concentration in atmospheric air, etc. Therefore, naturally, the desire to use this pattern in the interests of man, give it a more or less accurate quantitative expression.
As is known, mathematical concept of function apply to describe the links between variables f.which puts in line with each specific value of an independent variable x. defined value of the dependent variable y.. . This kind of unambiguous relationships between variables x. and y. Call functional. However, this kind of communication in natural objects is far from always. Therefore, the dependence between biological, as well as environmental signs is not functional, but a statistical nature, when in the mass of homogeneous individuals, a certain value of one feature considered as an argument corresponds to not the same numerical significance, but a whole range of distributing numerical variations The values \u200b\u200bof another feature considered as a dependent variable, or function. This kind of dependence between variables is called correlation or correlation ..
Functional bonds can be easily detected and measured on single and group objects, but this cannot be done with correlation bonds, which can be studied only on group objects by methods of mathematical statistics. The correlation bond between the signs is linear and nonlinear, positive and negative. The task of correlation analysis is reduced to establishing the direction and form of communication between varying signs, the measurement of its grindiness and, finally, to verify the accuracy of selective correlation indicators.
Dependence between variables X. and Y. It can be expressed analytically (with the help of formulas and equations) and graphically (as a geometric location in the system of rectangular coordinates). The graph of correlation addiction is built by the equation function or called regression. Here and - the average arithmetic found on the condition that X. or Y. Some values \u200b\u200bwill accept x. or y.. These medium are called conditional.
11.1. Parametric communication indicators
Correlation coefficient. Conams between variable values x. and y. You can set by matching the numeric values \u200b\u200bof one of them with the corresponding values \u200b\u200bof the other. If the other increases with an increase in one variable, it indicates positive communication between these values, and vice versa, when an increase in one variable is accompanied by a decrease in the value of another, this indicates negative communication.
To characterize the connection, its direction and degree of conjugacy of variables are used by the following indicators:
linear addiction - correlation coefficient;
nonlinear - correlation relation.
To determine the empirical correlation coefficient, the following formula is used:
![]()
![]() . (1)
. (1)
Here s. x. and s. y. - Medium quadratic deviations.
The correlation coefficient can be calculated without resorting to the calculation of medium-sized quadratic deviations, which simplifies computational work, according to the following similar formula:
![]()
![]() . (2)
. (2)
The correlation coefficient is a dimensionless number in the range from -1 to +1. In case of independent variation of signs, when the relationship between them is completely absent ,. The stronger the conjugacy between the signs, the higher the correlation coefficient value. Therefore, with this indicator characterizes not only the presence, but also the degree of conjugacy between the signs. With a positive or direct connection, when large values \u200b\u200bof one feature correspond to the greatest values \u200b\u200bof the other, the correlation coefficient has a positive sign and is in the range of 0 to +1, with a negative or feedback, when smaller values \u200b\u200bof the other correspond to the large values \u200b\u200bof one feature, the correlation coefficient accompanied by a negative sign and is ranging from 0 to -1.
The correlation coefficient was widely used in practice, but it is not a universal indicator of correlation bonds, since only linear connections are able to characterize, i.e. expressed by the linear regression equation (see the topic 12). If there are non-linear dependence between varying signs, other communication indicators are used, discussed below.
Calculation of the correlation coefficient. This calculation is produced in different ways and in different ways depending on the number of observations (sampling). Consider separately the specifics of calculating the correlation coefficient in the presence of small samples and samples of large volume.
Small samples. In the presence of small samples, the correlation coefficient is calculated directly by the values \u200b\u200bof the conjugate signs, without prior to a grouping of sample data into variation bands. For this, the above formulas (1) and (2) are served. More convenient, especially in the presence of multivalued and fractional numbers, which are expressed by the variant h. i. and y. i. from average and, the following work formulas are served:
where ![]()
![]() ;
;
![]()
![]() ;
;
Here x. i. and y. i. - Paired versions of conjugate signs x. and y.; and -s-an arithmetic; - the difference between the pair options of conjugate signs x. and y.; n. - Total number of paired observations, or the amount of selective aggregate.
The empirical correlation coefficient, as any other selective indicator, serves as an assessment of its general Parameter ρ And as a random value is accompanied by an error:
The ratio of the selective correlation coefficient to its error serves as a criterion for checking the zero hypothesis - the assumption that in the general population, this parameter is zero, i.e. . Zero hypothesis reject at the accepted significance level α , if a
Values \u200b\u200bof critical points t. st. For different levels of significance α and the number of degrees of freedom are given in Table 1 applications.
It is established that when processing small samples (especially when n.< 30 ) Calculation of the correlation coefficient according to formulas (1) - (3) gives several underestimated estimates of the general parameter ρ . It is necessary to make the following amendment:
fisher Z-Conversion. Proper use of the correlation coefficient involves the normal distribution of the two-dimensional set of conjugate values \u200b\u200bof random variables x. and y.. From mathematical statistics, it is known that with a significant correlation between variables, i.e. when R. xY. > 0,5 The selective distribution of the correlation coefficient for a larger number of small samples taken from the normally distributing general population is significantly deviated from the normal curve.
Given this circumstance R. Fisher Found a more accurate way to estimate the general parameter to the value of the selective correlation coefficient. This method comes down to replace R. xY. The transformed value z, which is associated with the empirical correlation coefficient, as follows:
The distribution of the value Z is almost unchanged in form, as little depends on the size of the sample and on the value of the correlation coefficient in the general population, and approaches normal distribution.
The criterion for the reliability of the indicator Z is the following attitude:
Zero hypothesis is rejected at the accepted significance level α and the number of degrees of freedom. Values \u200b\u200bof critical points t. st. Led in table 1 applications.
Application z-transform Allows you to evaluate the statistical significance of the selective correlation coefficient, as well as the difference between the empirical coefficients, when the need arises.
Minimum sample size for accurate estimate of the correlation coefficient. You can calculate the size of the sample for the specified value of the correlation coefficient, which would be sufficient to refute the zero hypothesis (if the correlation between the signs Y. and X. really exists). For this serves as the following formula:
where n. - the desired sample size; t. - the value specified according to the adopted level of significance (better for α \u003d 1%); z. - Transformed empirical correlation coefficient.
Big samples. In the presence of numerous source data, they have to be grouped into variational rows and, constructing a correlation grid, the difference in its cells (cells) General frequencies of conjugate rows. The correlation grille is formed by the intersection of rows and columns, the number of which is equal to the number of groups or classes of correlated rows. Classes are located in the top string and in the first (left) column of the correlation table, and the total frequencies indicated by the symbol f. xY. - In the cells of the correlation lattice, which makes up the main part of the correlation table.
Classes placed in the top line of the table are usually located from left to right in an increasing order, and in the first column of the table - from top to bottom in decreasing order. With this location of the class of variational series, their total frequencies (if there is a positive connection between the signs Y. and X.) They will be distributed through the lattice cells in the form of an ellipse diagonally from the lower left corner to the upper right corner of the lattice or (in the presence of a negative connection between the signs) in the direction from the upper left corner to the lower right corner of the lattice. If frequency f. xY. It is distributed over the cells of the correlation lattice more or less evenly, without forming an ellipse figure, it will indicate the absence of correlation between the signs.
Frequency distribution f. xY. According to the cells of the correlation lattice, only a general idea of \u200b\u200bthe presence or absence of communication between the signs is given. Denote or less just because of the value and sign correlation coefficient. When calculating the correlation coefficient with a preliminary grouping of sample data in the interval variation bands should not be taken too wide class intervals. Rough grouping is much stronger than the value of the correlation coefficient than this takes place when calculating the average values \u200b\u200band variation indicators.
Recall that the magnitude of the class interval is determined by the formula
where x. max , x. mIN. - Maximum and minimum combination options; TO - The number of classes to which the characterization of the feature should be divided. Experience has shown that in the field of correlation analysis, the magnitude TO It can be addicted to the sample size of approximately as follows (Table 1).
Table 1
|
Sampling volume |
Meaning K. |
|
50 ≥ N\u003e 30 |
|
|
100 ≥ N\u003e 50 |
|
|
200 ≥ N\u003e 100 |
|
|
300 ≥ N\u003e 200 |
Like other statistical characteristics calculated with the preliminary grouping of the initial data into variational series, the correlation coefficient is determined by different methods that give completely identical results.
Method of works. The correlation coefficient can be calculated using the basic formulas (1) or (2), making a correction to the repeatability of the version in the dimeric totality. At the same time, simplifying symbolism, deviations from their averages denote by but. and. Then formula (2), taking into account the repeatability of deviations, will take the following expression:
The reliability of this indicator is estimated by the Student's criterion, which represents the ratio of the selective correlation coefficient to its error determined by the formula
Hence, and if this value exceeds the standard value of the Student ST Criteration for the degree of freedom and the level of significanceα (see table 2 of the applications), then the zero hypothesis is rejecting.
Method of conditional averages. When calculating the correlation coefficient of deviation option ("classes"), it is possible to find not only from the average arithmetic and, but also on the conditional average and x and a y. In this case, the method in the numerator of formula (2) make a correction and the formula acquires the following form:
where f. xY. - frequencies of the classes of one and other rows of distribution; and, i.e. Deviations of classes from conditional averages related to the size of class intervals λ ; n. - the total number of paired observations, or sampling; and - the conditional moments of the first order, where f. x. - Row frequencies H., but f. y. - Row frequencies Y.; s. x. and s. y. - Medium quadratic deviations of the series X.and Y.calculated by the formula.
The method of conditional averages has an advantage over the method of works, as it makes it possible to avoid transactions with fractional numbers and give the same (positive) sign of deviations a. x. and a. y. that simplifies the technique of computational work, especially in the presence of multivalued numbers.
Evaluation of the difference between correlation coefficients. When comparing the correlation coefficients of two independent samples, the zero hypothesis is reduced to the assumption that in the general population, the difference between these indicators is zero. In other words, it should be proceeded from the assumption that the difference observed between the compaable empirical correlation coefficients occurred by chance.
To check the zero hypothesis, the T-criterion of Student is served, i.e. The ratio of the difference between the empirical correlation coefficients R. 1 and R. 2 To its statistical error determined by the formula:
where s. R1 and s. R2 - Errors of compared correlation coefficients.
Zero hypothesis is refuted, provided that the significance rate has α and the number of degrees of freedom.
It is known that a more accurate assessment of the accuracy of the correlation coefficient is obtained by transferring R. xY. Number z.. Not exception and assessment of the difference between selective correlation coefficients R. 1 and R. 2 , especially in cases where the latter are calculated on the samples of a relatively small volume ( n.< 100 ) and in its absolute value significantly exceeds 0.50.
The difference is estimated by the Student t-criterion, which is built in relation to this difference to its error calculated by the formula
The zero hypothesis is rejecting if for the accepted level of significanceα.
Correlantion. To measure nonlinear relationships between variables x. and y. use an indicator that is called correlation relationshipthat describes the bilateral connection. The design of the correlation relationship involves a comparison of two types of variation: variability of individual observations with respect to the individual average and variations of the private averages themselves compared with the total average value. The smaller part will be the first component in relation to the second, the topics of communication will be greater. In the limit, when there is no variation of individual signs near private averages, it will be extremely large. Similarly, in the absence of variability of private averages, the coupling is minimal. Since this ratio of variation can be considered for each of the two signs, two indicators of the tightness are obtained - h. yx. and h. xY. . The correlation relationship is the value of relative and can take values \u200b\u200bfrom 0 to 1. At the same time, the coefficients of the correlation ratio are usually not equal to each other, i.e. . Equality between these indicators is feasible only with strictly linear relationships between the signs. The correlation relationship is a universal indicator: it allows you to characterize any form of correlation and linear, and nonlinear.
Correlation ratios h. yx. and h. xY. Determine the methods discussed above, i.e. The method of works and method of conditional averages.
Method of works. Correlation ratios h. yx. and h. xY. Determine the following formulas:
where and - group dispersions,
a and - general dispersions.
Here and - general average arithmetic, and - group average arithmetic; f. yi. - Row frequencies Y., but f. xI - Row frequencies X.; k. - the number of classes; n. - The number of varying signs.
Formulas for calculating the correlation ratios are as follows:
Method of conditional averages. Determining the coefficients of the correlation ratio by formulas (15), deviations of class option x. i. And Y i can be taken not only from average arithmetic and, but also from conditional average and x and a y. In such cases, group and general deviatages are calculated by formulas and, as well as, and, wherees.
In the deployed form of formula (15) look like this:
![]()
![]() ;
;
![]()
![]() . (17)
. (17)
In these formulas and - deviations of classes from conditional averages, abbreviated by the value of class intervals; Values a. y. and a. x. Number of natural rows are expressed: 0, 1, 2, 3, 4, ....ostal symbols are explained above.
Comparing the method of works with the method of conditional average, it is impossible not to notice the advantage of the first method, especially in cases where you have to deal with multi-valued numbers. Like other selective indicators, the correlation relationship is an estimate of its general parameter and, as a random value, is accompanied by an error determined by the formula
The accuracy of the correlation estimation can be checked by the T-criterion of Student. H 0 is a hypotese proceeds from the assumption that the general parameter is zero, i.e. The following condition should be performed:
for the number of degrees of freedom and the level of significanceα.
Coefficient of determination. To interpret the values \u200b\u200btaken by the indicators of the tightness of the correlation; determination coefficientswhich show what the proportion of variations of one feature depends on the variation of another feature. In the presence of a linear connection, the determination coefficient is the square of the correlation coefficient R2 XY, and with non-linear dependence between the signs y. and x. - Square of the correlation ratio H2 YX. The determination coefficients give reason to build the following exemplary scale, allowing to judge the tightness of the connection between the signs: with the connection is considered to be average; Indicates a weak connection and only when one can judge a strong connection, when about 50% of the characterization of the feature Y. Depends on the variation of the feature X..
Evaluation of communication form. With strictly linear relationships between variables y. and x. Equality is carried out. In such cases, the coefficients of the correlation relationship coincide with the value of the correlation coefficient. The coincidence in this value and the determination coefficients, i.e. . Consequently, in terms of the difference between these values, one can judge the form of correlation dependence between variables y. and x.:
Obviously, with a linear connection between variables y. and x. The indicator Γ will be zero; If the connection between variables y. and x. nonlinear, γ\u003e 0.
The indicator Γ is an estimate of the general parameter and, as a random value, needs to be verified. This proceeds from the assumption that the relationship between values y. and x. Linear (zero hypothesis). Check this hypothesis allows Fisher's F-Criteria:
where a. - the number of groups, or classes of variational series; N - sampling volume. The zero hypothesis is rejected if applications are horizontally (found horizontally), (found in the first column of the same table) and the adopted level of significanceα.
Determination of the significance of the correlation
Classification of correlation coefficients
Correlation coefficients are characterized by force and significance.
Classification of correlation coefficients for strength.
Classification of correlation coefficients to significance.
2 of these classifications should not be confused, as they define different characteristics. The strong correlation may be random and, it became unreliable. Especially often it happens in the sample with a small volume. And in a large sample, even a weak correlation may be highly valued.
After calculating the correlation coefficient, it is necessary to put forward statistical hypotheses:
H 0: The correlation rate is not significantly different from zero (it is random).
H 1: The correlation rate is significantly different from zero (it is non-random).
Checking the hypothesis is compared to the resulting empirical coefficients with table critical values. If empirical significance reaches critical or exceeds it, then the zero hypothesis is rejected: R EMF ≥ R kr but, þ H 1. In such cases, they conclude that the accuracy of differences is detected.
If empirical significance does not exceed the critical, then the zero hypothesis is not rejected: R EMF< r кр Þ Н 0 . В таких случаях делают вывод, что достоверность различий не установлена.
Statistics / Correlation
Calculation of the matrix of paired coefficients
correlation
To calculate the matrix of paired correlation coefficients, call the menu Correlation matrices module Basisstatisticians.


Fig. 1 module panel Basic statistics
The main stages of the correlation analysis in the STATST_S system will look at the data of the example (see Fig. 2). The initial data is the results of observations of the activities of 23 enterprises of one of the industries.


Fig.2 Initial data
Table graphs contain the following indicators:
Profitable - profitability,%;
The share of the slave is the share of workers in the composition of the PPP, units;
Fondootd - Fondo studios, units;
Osnfonds - the average annual value of the main production facilities, million rubles;
Unpropented - non-production costs, thousand rubles. It is required to investigate the dependence of profitability from other
gih indicators.
Suppose that the signs under consideration in the general aggregate are subject to the normal distribution law, and these observations are a sample of the aggregate.
Calculate paired correlation coefficients between all variables. After selecting the line Correlation matrices A dialog box appears on the screen. Pearson correlations. The name is due to the fact that for the first time this coefficient was Pearson, Edgeworth and Veldon.
Select variables for analysis. To do this, there are two buttons in the dialog box: Quad. the matrix (one list) and Right. the matrix (two list).


Fig. 3 Correlation Analysis Dialog
The first button is designed to calculate the matrix of custom. symmetric species with pairwise correlation coefficients of all combinations of variables. If you use all the indicators when analyzing, you can press the button in the variable selection dialog box. Choose all. (If the variables are not in a row, you can choose to select a mouse click with simultaneously pressing the key Ctrl)


If you click Details. Dialog box, for each variable long names will be displayed. By clicking this button again (it will be called Briefly), I get short names.
Button Information Opens the window for the selected re-in which you can view its characteristics: long name, display format, sorted list of values, descriptive statistics (number of values, mean, standard deviation).
After selecting the variables, click OK or button Correlatia dialog box Correlation Pearson. The calculated correlation matrix appears on the screen.
Significant correlation coefficients on the screen are highlighted in red.
In our example, the profitability indicator was most associated with the indicators fondoOstitch (link direct) and production expenses (Feedback, involving the ending V with increasing x). But how closely the signs are mutually satisfied? The tight is considered to be the connection with the values \u200b\u200bof the coefficient of module more than 0.7 and weak - less than 0.3. Thus, with further constructing the regression equation, it should be limited to the indicators of "fund-student" and "non-productive expenses" as the most informative.
However, in our example there is a phenomenon. multicolors, When there is a link between the independent variables themselves (the pair correlation coefficient in the module is greater than 0.8).
OPTION The rectangular matrix (two list of variables) opens a dialog box for selecting two variable lists. Pose as in the picture

As a result, we obtain a rectangular correlation matrix containing only the correlation coefficients with a dependent variable.


If option is installed Corr. Matrix (samples meaningful),then after clicking the button Correlation A matrix with coeoph will be built, isolated at the level of significance r.


If option is selected Detailed table results, then on fire button Correlation, we obtain a table that contains not only correlation coefficients, but also medium, mill-dart deviations, the coefficients of the regression equation, its bodie member in the regression equation and other statistics


When the variables have a small relative variation (the ratio of the standard deviation to the average less than 0.00 billion 20,000,0001), a higher degree of evaluation is required. It can be set by placing the calculation option with the increasing accuracy of the Pearson correlation dialog box.
The mode of operation with missed data is determined by the desigid removal of PD. If you choose it, then Statіst ignores all observations that have skipping. In the opposite case, their pairwise removal is made.
A marked mode to display the long variable names will result in a table with long variable names.
Graphic image of correlation dependencies
The Pearson Correlation dialog box contains a number of buttons to obtain a graphic image of correlation dependencies.
The 2M scattering option builds a scattering chart sequence for each selected variable. The window for their choice is identical to Figure 6. On the left, you should specify the vibrant variables, on the right independent - profitable. By clicking OK, we obtain a graph on which the alignation of the regression direct and trust boundaries of the rognosis will be depicted.
The linear correlation coefficient gives the most objective assessment of the tone of communication, if the location of the points in the coordinate system resembles a direct line or an elongated ellipse, if the points are located in the form of a curve, then the orregulation coefficient gives an affected rating.
On the basis of the schedule, we can once again confirm the relationship between profitability and foundation indicators, as these observations are located in the form of an inclined ellipse. It must be said that the relationship is considered the fact that there is a blister point to the main axis of the ellipse.
In our example, the change in the indicator of the foundation per unit will lead to a change in profitability by 5.7376%.
Let's look at the impact of non-productive expenses on the value of profitability. To do this, build a similar schedule
The analyzed data is already less reminded by its ellipse form, and the correlation coefficient is somewhat lower. The found value of the regression coefficient shows that with an increase in non-production expenses per 1,000 rubles, profitability decreases by 0.7017%.
It should be noted that the construction of multiple regression (considered in subsequent chapters), when the equation is at the same time both features, leads to other values \u200b\u200bof the regression coefficients, which is explained by the interaction explaining the variables among themselves.
When using a point name buttons on the scattering diagram, you will get the corresponding numbers or names if they are predefined.
The following option indicating the graphics of the matrix builds an outrits of scattering diagrams for selected variables.
looking graphic element of this matrix contains a correlate-yonic fields formed by the corresponding variables with
married on them regression line.
When analyzing the matrix of scattering diagrams, attention should be paid to those charts whose regression lines have a significant slope to the X axis, which suggests the existence of the interdependence between the corresponding initial signs.
The scattering SM option builds a three-dimensional correlation field for selected variables. If the name button is used, the points on the scattering diagram will be marked by numbers or names of the corresponding observations if they have them.
The graphic option surface builds the SM to the scattering diagram for the selected three variables together with the fitted second order surface.
The option Catagor. The scattering diagrams in turn builds the cascade of correlation fields for the selected indicators.
After pressing the corresponding button, the program will ask the user to make two of their set of selected previously using the variables button. Then a new one will appear on the screen.
the query window for the task of a grouping variable, on the basis of which all available observations will be classified.
The result is the construction of correlation fields in the cuts of observation groups for each pair of variables, reeperative to different lists
3.4. Calculation of private and multiple coefficientscorrelations
To calculate the private and multiple coefficients of Cor. Relations call module Multiple regressionusing the module switch button. The following dialog box appears on the screen:
Press the button Variables, choose variables for analysis: on the left dependent - profitability, and on the right of independent - fondoOstitch and unproductive expenses. The remaining variables will not participate in further analysis - based on the correlation analysis, they are recognized as non-informative for the regression model.
In field File input Common source data is proposed as input data, which is a table with variables and observations, or a correlation matrix. The correlation matrix can be pre-created in the Multiple regression module itself or calculate the quick basic statistics with the help of the option.
When working with the source data file, you can set the rendering of skipping:
Build removal. If this option is selected, only those observations that do not have missed values \u200b\u200bin all selected variables are used in the analysis.
Substitution average. The missed values \u200b\u200bin each variable are replaced with an average calculated by the existing complete observations.
Parental deletion of missed data. If this option is selected, then when calculating pair correlations, observations that have missed values \u200b\u200bin the corresponding variable pairs are removed.
In field Type of regression The user can choose a standard or fixed nonlinear regression. By default, a standard analysis of multiple regression is selected, in which the standard correlation matrix of all selected variables is calculated.
Mode Fixed nonlinear regression Allows you to carry out various transformations of independent variables. Option Conduct analysis By default, the settings appropriate to the definition of standard regression delight, including a free member. If this option is canceled, then when you click on the button ok starting panel, the definition of the model definition dialog box in which you are an ejet to choose as a type of regression analysis (for example, step-by-step, crest, etc.) and other options.
Checking the Line option checkbox Show descriptive descriptiveCorr. Matrians and clicking OK, we obtain a dialog box with statistical data characteristics.
In it, you can view detailed descriptive statistics (including the number of observations by which the correlation coefficient has been calculated for each pair of variables). To continue the analysis and open the model determinants dialog box, click OK.
If the analyzed indicators have an extremely small relative dispersion calculated as the overall dispersion divided by the average, then check the checkbox near the option High accuracy calculations To obtain more accurate values \u200b\u200bof the correlation matrix elements.
By installing all the necessary parameters in the dialog box. Multiple regression, Press OK and get the results of the required calculations.
According to our example, the multiple correlation coefficient turned out to be 0.61357990 and, accordingly, the determination coefficient is 0.37648029. Thus, only 37.6% of the dispersion of the indicator "profitability" is explained by the measurement of the indicators of "fundo-studies" and "non-production costs". Such a low value indicates a lack of number of factors introduced into the model. Let's try to change the number of independent variables by adding the list of re-"main funds" (Introduction to the model of the indicator "The share of workers in the PPP" leads to multicolleniance, which is unacceptable). The determination coefficient increased somewhat, but not so much to significantly improve the results - its value was about 41%. Obviously, our cottage requires additional research to identify factors affecting profitability.
The significance of the multiple correlation coefficient is pro-doubtlessly on the Fischer's F-Criteria table. The hypothesis of its significance is rejected if the probability value of the deviation exceeds the specified level (most often taken a \u003d 0.1, 0.05; 0.01 0.001). In our example p \u003d 0.008882< 0.05, что свидетельствует о значимости коэффициента.
The results table contains the following graphs:
Beta coefficient (c) - Standardized regression coefficient of relevant variable;
Private correlation - Private coefficients of the correlation between the appropriate variable and dependent, when fixing the influence of the remaining in the model.
The private correlation coefficient between profitability and fund-student in our example is 0.459899. This means, after entering into the model of an indicator of non-productive ras-evi, the influence of fund-paying on profitability somewhat is somewhat - from 0.49 (the value of the pairwise correlation coefficient) 0.46. A similar coefficient for indicator of non-derivative expenses has also decreased - from 0.46 (the value of the pair ratio of the correlation) to 0.42 (they take a value of the module), characterizes the change in the connection with the dependent variable of the input in the model of the foundation indicator.
Party correlation is a correlation between an uncorrected dependent variable and the corresponding non-dependent taking into account the influence of the remaining included in the model.
Tolerance (defined as 1 minus the square of the plural correlation between the corresponding variable and all independent variables in the regression equation).
The determination coefficient is the square of the multiple correlation coefficient between the corresponding independent variable and all other variables included in the regression equation.
1-values \u200b\u200b- the calculated value of the Student's criterion for testing the hypothesis about the significance of the private correlation coefficient with the specified (in brackets) by the number of degrees of freedom.
r-level! - the probability of deviation of the hypothesis on the significance of the private correlation coefficient.
In our case, the obtained value of p for the first coefficient (0.031277) is less than the selected \u003d 0.05. The value of the second coefficient is somewhat higher (0.050676), which indicates its insignificance at this level. But it is significant, for example, at \u003d 0.1 (in ten cases from one hundred hypothesis, it will be nevertheless incorrect).
