Según la muestra, encuentre una función empírica. Función empírica de distribución
Promedio selectivo.
Supongamos que estudiar el agregado general en relación con la característica cuantitativa X, se recupera la muestra del volumen N.
El medio selectivo se denomina valor aritmético promedio del signo del conjunto de muestras.
![]()
Dispersión selectiva.
Para observar la dispersión de la característica cuantitativa de los valores de la muestra alrededor de su valor promedio, se introduce una característica resumen: la dispersión selectiva.
La dispersión selectiva se denomina cuadrados de aritmética promedio de la desviación de los valores observados de la característica de su valor promedio.
Si todos los signos de la muestra son diferentes, entonces

Dispersión fija.
La dispersión selectiva es una estimación sesgada de la dispersión general, es decir. La expectativa matemática de la dispersión selectiva no es igual a la dispersión general estimada, pero igual
![]()
Para corregir la dispersión de la muestra, es suficiente para multiplicarlo por fracción.
Coeficiente de correlación selectivaubicado por fórmula

donde - Desviaciones cuadráticas promedio selectivas de cantidades y.
El coeficiente de correlación selectiva muestra las líneas de conexión lineal entre y: cuanto más cercano a uno, más fuerte, la conexión lineal entre y.
23. El polígono de frecuencia se llama línea quebrada, segmentos de los cuales los puntos de conexión. Para construir el polígono de frecuencia en el eje de abscisa, las variantes se depositan y en el eje de la ordenada, las frecuencias correspondientes correspondientes a ellos y conectan los puntos con las líneas rectas.
El polígono de frecuencia relativa se construye de la misma manera, excepto que las frecuencias relativas se posponen en el eje de ordenación.
El histograma de frecuencia se denomina figura escalonada que consiste en rectángulos, cuyas bases son intervalos parciales con un largo h, y la altura es igual a la proporción. Para construir un histograma de frecuencia en el eje de abscisas, se depositan intervalos parciales y hay segmentos, eje de abscisa paralelas a una distancia (altura). El área del rectángulo I-TH es: la cantidad de frecuencias del intervalo I-O variante, por lo tanto, el área del histograma de frecuencia es igual a la suma de todas las frecuencias, es decir, Muestreo.


Función empírica de distribución
dónde n x. - El número de valores selectivos más pequeños. x.; nORTE. - Muestreo.
22 Realizar los conceptos básicos de las estadísticas matemáticas.
. Los conceptos básicos de estadísticas matemáticas. Agregado general y muestra. Serie variacional, fila estadística. Muestra a la parrilla. Serie estadística a la parrilla. Frecuencia de polígono. Función de distribución selectiva y histograma.
Agregado general- Todos los muchos objetos disponibles.
Muestra - Un conjunto de objetos seleccionados al azar de la población general.
La secuencia de la opción registrada en orden ascendente se llama variacióncerca, y la lista de opciones y las frecuencias correspondientes o frecuencias relativas. pegarse: Té seleccionado de la población general.
Polígonolas frecuencias se denominan una línea quebrada, los segmentos de los cuales se conectan los puntos.
Frecuencia de histograma Llaman a una figura escalonada que consiste en rectángulos, cuyas bases sirven como intervalos parciales con longitud H, y la altura es igual a la proporción.
Función de distribución selectiva (empírica) Función de llamada F *(x.) Definiendo para cada valor h. Frecuencia de eventos relativos X.< x.
Si se investiga algún signo continuo, la serie Variatal puede consistir en un número muy grande de números. En este caso es más conveniente usar. muestra a la parrilla. Para obtenerlo, el intervalo en el que se concluyen todos los valores de signo observados, divididos en varios intervalos parciales iguales. h.y luego encontrar para cada intervalo parcial n I. - la suma de las frecuencias de la opción en i.- I Intervalo.
20. Según la ley de grandes cantidades no debe entenderse como una ley general asociada con grandes números. La ley de grandes números es un nombre generalizado de varios teoremas, desde los cuales se deduce que con un aumento ilimitado en el número de pruebas, los valores promedio tienden a algunas constantes.
Estos incluyen los teoremas de Chebyshev y Bernoulli. El teorema de Chebyshev es la ley más común de grandes números.
La prueba de los teoremas unidos por el término "Ley de grandes números" es la desigualdad de Chebyshev, según la cual se establece la probabilidad de desviación de su expectativa matemática:
![]()
19 Distribución de Pearson (Hee - Square) - Distribución de la variable aleatoria
donde las variables aleatorias X 1, x 2, ..., x n Independiente y tener la misma distribución. NORTE.(0,1). Al mismo tiempo el número de componentes, es decir, nORTE.Se llama "el número de grados de libertad" de la distribución de Hee - Square.
La distribución de Chi-Square se usa al evaluar la dispersión (utilizando un intervalo de confianza), al verificar las hipótesis de consentimiento, homogeneidad, independencia,
Distribución t. El estudiante es la distribución de la variable aleatoria.
donde las variables aleatorias U. y X. independiente U. Tiene la distribución normal de distribución. NORTE.(0,1), y X. - Distribución Hee - cuadrado con NORTE. grados de libertad. Donde nORTE. Llamado el "número de grados de libertad" de la distribución del estudiante.
Se utiliza al evaluar la expectativa matemática, del valor de pronóstico y otras características utilizando intervalos de confianza, al verificar las hipótesis sobre los valores de las expectativas matemáticas, los coeficientes de la dependencia de la regresión,
La distribución de Fisher es una distribución de variables aleatorias.
La distribución de Fisher se usa al verificar las hipótesis sobre la adecuación del modelo en el análisis de regresión, sobre la igualdad de dispersiones y en otras tareas de estadísticas aplicadas.
18Regresión lineal Es una herramienta estadística utilizada para predecir los precios futuros basados \u200b\u200ben datos pasados, y generalmente se aplica para determinar cuándo se sobrecalientan los precios. El método cuadrado más pequeño se utiliza para construir la línea recta "más adecuada" a través de una serie de valores de precios. Los puntos de precio utilizados como datos de entrada pueden ser cualquiera de los siguientes valores: apertura, cierre, máximo, mínimo,
17. Las variables aleatorias bidimensionales se denominan un conjunto ordenado de dos variables aleatorias o.
Ejemplo. Se adjuntan dos cubos de juego. - El número de puntos cayó en el primer y segundo cubos, respectivamente.
Una forma universal de establecer la ley de la distribución de una variable aleatoria bidimensional es una función de distribución.
15.m.OO Variables aleatorias discretas
Propiedades:
1) METRO.(C.) = C., C. - constante;
2) METRO.(Cx.) = Cm.(X.);
3) METRO.(X 1 + X 2) = METRO.(X 1) + METRO.(X 2), dónde X 1, X 2 - Variables aleatorias independientes;
4) METRO.(X 1 x 2) = METRO.(X 1)METRO.(X 2).
La expectativa matemática de la suma de variables aleatorias es igual a la suma de sus expectativas matemáticas, es decir,
La expectativa matemática de la diferencia de las variables aleatorias es igual a la diferencia en sus expectativas matemáticas, es decir,
La expectativa matemática del trabajo de las variables aleatorias es igual al producto de sus expectativas matemáticas, es decir,
Si todos los valores del valor aleatorio aumentan (reducen) al mismo número c, entonces su expectativa matemática aumentará (disminución) para el mismo número
14. Exponencial(exponencial) Ley de distribución X. Tiene una ley indicativa (exponencial) de distribución con parámetros λ\u003e 0, si su densidad de probabilidad es:
![]()
Valor esperado: .
Dispersión :.
La ley indicativa de la distribución desempeña un papel importante en la teoría del servicio masivo y la teoría de la confiabilidad.
13. La Ley de Distribución Normal se caracteriza por la frecuencia de fallas A (T) o la densidad de probabilidad de fallas F (t) de la forma:
 , (5.36)
, (5.36)
donde σ-rms desviación de x.;
mETRO. x. - Expectativa matemática de SV. x.. Este parámetro a menudo se conoce como el centro de dispersión o el valor más probable de H..
x.- Valor aleatorio para el cual puede tomar tiempo, valor actual, valor de voltaje eléctrico y otros argumentos.
La ley normal es una ley de dos parámetros, para registrar lo que necesita saber m x. y σ.
La distribución normal (distribución de GAUSS) se usa para evaluar la confiabilidad de los productos a los que afectan una serie de factores aleatorios, cada uno de los cuales afecta ligeramente al efecto resultante.
12. Derecho de distribución uniforme. Cantidad aleatoria continua X. tiene una ley uniforme de distribución en el segmento [ uNA., b.] Si su densidad de probabilidad es constante en este segmento y es cero fuera de ella, es decir,

Designacion :.
Valor esperado: .
Dispersión :.
Valor aleatorio H.Se llama a la ley distribuida por la ley uniforme en el segmento. número aleatorio De 0 a 1. Sirve como material de origen para obtener variables aleatorias con cualquier ley de distribución. La ley de distribución uniforme se utiliza para analizar los errores de redondeo durante los cálculos numéricos, en una serie de tareas de mantenimiento masivo, con el modelado estadístico de observaciones subordinadas a la distribución especificada.
11. Definición. Densidad de distribución Las probabilidades de una variable aleatoria continua X se llama una función f (x) - El primer derivado de la función de distribución f (x).
Densidad de distribución también llamada función diferencial. Para describir una variable aleatoria discreta, la densidad de distribución es inaceptable.
El significado de la densidad de distribución es que muestra la frecuencia con la que aparece una célula aleatoria en algún vecindario del punto. h. Cuando la repetición de experimentos.
Después de administrar las funciones de distribución y densidad de distribución, se puede administrar la siguiente definición de una variable aleatoria continua.
10. La densidad de probabilidad, la densidad de la distribución de probabilidad del valor aleatorio X, es la función P (x) de modo que 
y con cualquier< b вероятность события a < x < b равна
.
Si p (x) es continuo, entonces con la probabilidad de la desigualdad X con suficientemente pequeña.< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
y, si f (x) diferenciar, entonces ![]()
Conferencia 13. El concepto de estimaciones estadísticas de las variables aleatorias.
Deje que se le sepa la distribución estadística de las frecuencias de la característica cuantitativa de X. denote mediante el número de observaciones bajo las cuales el valor de la característica inferior a x y a través de N es el número total de observaciones. Obviamente, la frecuencia relativa del evento X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Función empírica de distribución (Función de muestreo) Llame a una función que define para cada valor X Frecuencia de evento relativo x< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
A diferencia de la función de distribución de la muestra empírica, se llama la función de la distribución de la población general. función de distribución teórica.La diferencia entre estas funciones es que se determina la función teórica. probabilidadeventos X.< x, тогда как эмпирическая – frecuencia relativadel mismo evento.
Con crecimiento N Frecuencia de evento relativo x< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Propiedades de la función de distribución empírica.:
1) Los valores de la función empírica pertenecen al segmento.
2) - Función no decreciente
3) Si, la variante más pequeña, entonces \u003d 0 con, si es la mayor variante, entonces \u003d 1 en.
La función de distribución de la muestra empírica se utiliza para estimar la función teórica de la distribución de la población general.
Ejemplo. Construimos una característica empírica por muestreo:
| Opciones | |||
| Frecuencia |
Encuentre el tamaño de la muestra: 12 + 18 + 30 \u003d 60. La realización más pequeña es 2, por lo tanto \u003d 0 a x £ 2. el valor x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x> 10. Por lo tanto, la función empírica deseada tiene la forma:
Las propiedades más importantes de las estimaciones estadísticas.
Deje que se tome para estudiar un signo cuantitativo de la población general. Supongamos que de las consideraciones teóricas era posible instalar, qué exactamente La distribución tiene un signo y es necesario estimar los parámetros que se determina. Por ejemplo, si la función estudiada se distribuye en la población general normalmente, es necesario estimar la expectativa matemática y la desviación quadrática promedio; Si el signo tiene la distribución de Poisson, entonces es necesario estimar el parámetro L.
Por lo general, solo hay datos de muestreo, por ejemplo, los valores de la característica cuantitativa obtenidos como resultado de n observaciones independientes. Teniendo en cuenta cómo se pueden decir que las variables aleatorias independientes se pueden decir que encuentre la evaluación estadística del parámetro desconocido de la distribución teórica: significa encontrar la función de las variables aleatorias observadas, que proporciona un valor aproximado del parámetro estimado. Por ejemplo, para evaluar la expectativa matemática de la distribución normal, la función de la función realiza la aritmética promedio.
Para que las estimaciones estadísticas dan las aproximaciones correctas de los parámetros estimados, deben satisfacer algunos requisitos, entre los que se encuentran los requisitos más importantes. discapacidad y consistencia estimados.
Let - la evaluación estadística del parámetro desconocido de la distribución teórica. Supongamos por el volumen de muestra N, se encontró la estimación. Repetimos la experiencia, es decir. Extracto de la población general Otra muestra del mismo volumen y de acuerdo con sus datos, obtenemos otra evaluación. Repetir experiencia repetidamente, obtenemos diferentes números. La estimación se puede considerar como una cantidad aleatoria, y el número, como sus posibles valores.
Si la evaluación da valor aproximado. con exceso. Cada número es más del valor verdadero, como resultado, la expectativa matemática (valor promedio) de una variable aleatoria es mayor que :. Del mismo modo, si da una evaluación. con desventajaluego.
Por lo tanto, el uso de una evaluación estadística, cuya expectativa matemática no es igual al parámetro estimado, conduciría a errores sistemáticos (un signo). Si, por el contrario, garantiza de errores sistemáticos.
Entender Llame a una evaluación estadística, cuya expectativa matemática es igual al parámetro estimado con cualquier tamaño de muestra.
Desplazado Llame a una estimación que no cumpla con esta condición.
La estimación de la evaluación aún no garantiza la preparación de una buena aproximación para el parámetro estimado, ya que los valores posibles pueden ser fuertemente dispersado alrededor de su promedio, es decir,. La dispersión puede ser significativa. En este caso, la evaluación encontrada de acuerdo con una muestra, por ejemplo, puede eliminarse significativamente del valor medio y, por lo tanto, desde el parámetro más estimado.
Eficaz llame a una evaluación estadística, que, con un muestreo dado, tiene la dispersión más pequeña posible .
Al considerar las muestras de una gran cantidad a estimaciones estadísticas, se realiza el requisito consistencia .
Adinerado Se llama una evaluación estadística, que para N® ¥ tiende a probable en el parámetro estimado. Por ejemplo, si la dispersión de una estimación inestable para N® ¥ tiende a cero, entonces tal evaluación también es rica.
Determinación de la función de distribución empírica.
Deja que $ x $ sea un valor aleatorio. $ F (x) $ - la función de la distribución de esta variable aleatoria. Se llevaremos a cabo en los mismos países independientes entre sí, las condiciones de $ n $ experimentos en esta variable aleatoria. En este caso, obtenemos la secuencia de valores de $ X_1, \\ X_2 \\ $, ..., $ \\ x_n $, que se llama la muestra.
Definición 1.
Cada valor de $ X_I $ ($ i \u003d 1.2 \\ $, ..., $ \\ n $) se llama la opción.
Una de las estimaciones de la función de distribución teórica es la función de distribución empírica.
Definición 3.
La función empírica de la distribución $ F_N (X) $ se llama una función que determina por cada valor de $ x $ la frecuencia relativa del evento $ X \\
donde $ n_x $ es el número de la variante más pequeña que $ x $, $ n $ es el tamaño de la muestra.
La diferencia de la función empírica de lo teórico consiste en que la función teórica determina la probabilidad de un evento $ X
Propiedades de la función de distribución empírica.
Considere ahora varias propiedades básicas de la función de distribución.
El rango de valores de la función $ F_N \\ IZQUIERDA (X \\ Derecha) $ - CUT $$.
$ F_N \\ IZQUIERDA (X \\ Derecha) $ Función que no se rompa.
$ F_N \\ IZQUIERDA (X \\ Derecha) $ continuo en la función izquierda.
$ F_N \\ IZQUIERDA (X \\ Derecha) $ Función constante de forma establecida y aumenta solo en variables aleatorias $ x $
Deje que $ X_1 sea la más pequeña, y $ X_N $ es la opción más grande. Luego, $ F_N \\ Izquierda (X \\ Derecha) \u003d 0 $ con $ (x \\ le x) _1 $ y $ f_n \\ izquierda (x \\ derecha) \u003d 1 $ con $ x \\ ge x_n $.
Presentamos el teorema que une las funciones teóricas y empíricas entre sí.
Teorema 1.
Deje $ F_N \\ Izquierda (x \\ derecha) $: una función de distribución empírica, y $ F \\ izquierda (X \\ Derecha) $ es la función teórica de la distribución de la muestra general. Entonces se realiza la igualdad:
\\ [(\\ Mathop (LIM) _ (n \\ a \\ INFTY) (| F) _n \\ Izquierda (X \\ Derecha) -F \\ Izquierda (X \\ Derecha) | \u003d 0 \\) \\]
Ejemplos de tareas para encontrar la función de distribución empírica.
Ejemplo 1.
Deje que la distribución de la muestra tenga los siguientes datos registrados con la tabla:
Foto 1.
Encuentre el tamaño de la muestra, haga una función de distribución empírica y cree su horario.
Volumen de muestreo: $ n \u003d 5 + 10 + 15 + 20 \u003d $ 50.
Por la propiedad 5, tenemos que con $ x \\ le $ 1 $ f_n \\ izquierda (x \\ derecha) \u003d 0 $, y con $ x\u003e $ 4 $ f_n \\ izquierda (x \\ derecha) \u003d 1 $.
El valor de $ X.
El valor de $ X.
El valor de $ X.
Así, obtenemos:

Figura 2.

Figura 3.
Ejemplo 2.
20 ciudades fueron seleccionadas al azar de las ciudades de la parte central de Rusia, para las cuales se obtuvieron los siguientes datos a costa de los viajes en transporte público: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12 , 15, 15, 15, 13, 13, 12, 12, 15, 14, 14.
Cree una característica empírica de la distribución de esta muestra y cree su horario.
Escribimos los valores de muestreo en orden ascendente y consideramos la frecuencia de cada valor. Obtenemos la siguiente tabla:
Figura 4.
Volumen de muestreo: $ n \u003d $ 20.
Por la propiedad 5, lo tenemos en $ X \\ le 12 $ $ f_n \\ izquierda (x \\ derecha) \u003d 0 $, y con $ x\u003e 15 $ $ f_n \\ izquierda (x \\ derecha) \u003d 1 $.
El valor de $ X.
El valor de $ X.
El valor de $ X.
Así, obtenemos:

Figura 5.
Construye un gráfico de una distribución empírica:

Figura 6.
Originalidad: $ 92.12 \\% $.
Averigüe qué es la fórmula empírica. En la química, la EF es la forma más fácil de describir la conexión, de hecho, es una lista de elementos que forman un compuesto basado en su contenido porcentual. Cabe señalar que esta simple fórmula no describe pedido Los átomos en la conexión, simplemente indica qué elementos que consiste. Por ejemplo:
- Compuesto que consta de 40.92% de carbono; El 4,58% del hidrógeno y el 54.5% de oxígeno tendrán la fórmula empírica C 3 H4O3 (un ejemplo de cómo encontrar el efecto de este compuesto se considerará en la segunda parte).
Apoyar el término "porcentaje". La "tasa de interés" se denomina porcentaje de cada átomo individual en todo el compuesto en consideración. Para encontrar la fórmula compuesta empírica, debe conocer la composición porcentual de la conexión. Si encuentra una fórmula empírica como tarea, lo más probable es que se le proporcione interés.
- Para encontrar el porcentaje de compuesto químico en el laboratorio, se somete a algunos experimentos físicos, y luego, el análisis cuantitativo. Si no está en el laboratorio, no necesita hacer estos experimentos.
Tenga en cuenta que tendrá que lidiar con los átomos de Gram. Un átomo de gramo es una cierta cantidad de sustancia, cuya masa es igual a su masa atómica. Para encontrar un átomo de gram-átomo, debe utilizar la siguiente ecuación: El porcentaje del elemento en el compuesto se divide en peso atómico del elemento.
- Supongamos, por ejemplo, tenemos un compuesto que contiene 40.92% del carbono. La masa atómica de carbono es de 12, por lo que nuestra ecuación tendrá 40.92 / 12 \u003d 3.41.
Sepa cómo encontrar una relación atómica. Trabajando con el compuesto, tendrás más de un átomo de gramo. Después de encontrar todos los gramos de los átomos de su conexión, mírelos. Para encontrar una relación atómica, deberá elegir el valor más pequeño del gram-átomo que calculó. Luego será necesario dividir todos los átomos gramos con el gram-átomo más pequeño. Por ejemplo:
- Supongamos que está trabajando con un compuesto que contiene tres gramos-átomos: 1.5; 2 y 2.5. El más pequeño de estos números es 1.5. Por lo tanto, para encontrar la proporción de átomos, debe dividir todos los números en 1.5 y poner una relación entre ellos : .
- 1.5 / 1.5 \u003d 1. 2 / 1,5 \u003d 1.33. 2.5 / 1.5 \u003d 1.66. En consecuencia, la proporción de átomos es igual. 1: 1,33: 1,66 .
Observe cómo traducir los valores de los átomos en enteros. Al registrar la fórmula empírica, debe usar enteros. Esto significa que no puede usar los números como 1.33. Después de encontrar la actitud de los átomos, debe traducir números fraccionarios (como 1.33) en su totalidad (por ejemplo, 3). Para hacer esto, debe encontrar un entero, multiplicando a la cual cada número de proporción atómica, obtendrá enteros. Por ejemplo:
- Pruebe 2. Multiplique los números de la relación atómica (1, 1.33 y 1.66) por 2. Recibirá 2, 2.66 y 3.32. Estos no son enteros, por lo que 2 no encaja.
- Intente 3. Si multiplica 1, 1.33 y 1.66 por 3, tendrá 3, 4 y 5, respectivamente. En consecuencia, la relación atómica de enteros tiene la forma. 3: 4: 5 .
Como es bien conocido, la ley de la distribución de una variable aleatoria se puede establecer de varias maneras. Se puede hacer una cantidad aleatoria discreta utilizando una serie de distribución o función integral, y una cantidad aleatoria continua, con o una función integral, o diferencial. Considere los análogos selectivos de estas dos funciones.
Deje que haya un conjunto selectivo de valores de alguna cantidad aleatoria de volumen  y cada realización de esta totalidad se pone en línea con su frecuencia. Dejar que sea más
y cada realización de esta totalidad se pone en línea con su frecuencia. Dejar que sea más  - algún número válido, y
- algún número válido, y  - El número de valores selectivos de la variable aleatoria.
- El número de valores selectivos de la variable aleatoria.  , menor
, menor  .Then numero
.Then numero  es la frecuencia de los valores de los valores observados en la muestra. X., menor
es la frecuencia de los valores de los valores observados en la muestra. X., menor  ,
esos. FRECUENCIA DE EVENTOS
,
esos. FRECUENCIA DE EVENTOS 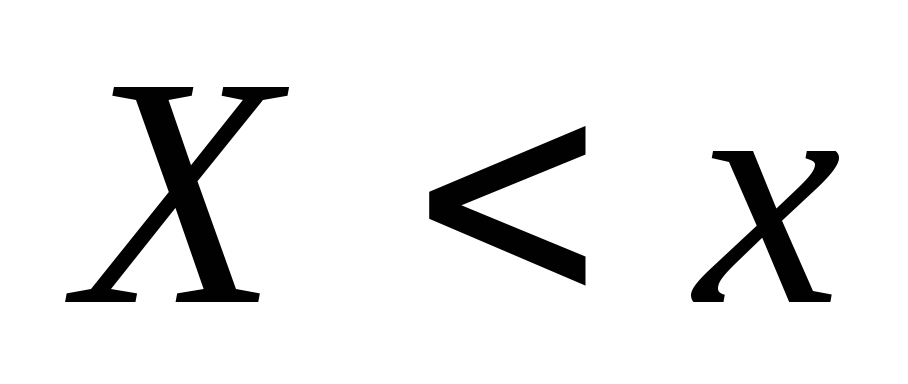 . Cuando cambia x. En general, el valor cambiará.
. Cuando cambia x. En general, el valor cambiará.  . Esto significa que la frecuencia relativa.
. Esto significa que la frecuencia relativa.  es una función del argumento.
es una función del argumento.  . Y, dado que esta función se encuentra de acuerdo con los datos selectivos obtenidos como resultado de experimentos, se llama selectivo o empírico.
. Y, dado que esta función se encuentra de acuerdo con los datos selectivos obtenidos como resultado de experimentos, se llama selectivo o empírico.
Definición 10.15. Función empírica de distribución Función de llamada (función de muestreo)  Definiendo para cada valor x. Frecuencia de eventos relativos
Definiendo para cada valor x. Frecuencia de eventos relativos  .
.
 (10.19)
(10.19)
En contraste con la función de distribución de la muestra empírica, la función de distribución. F.(x.) Población general llamada función de distribución teórica.. La diferencia entre ellos es esa función teórica. F.(x.)
Determina la probabilidad de un evento.  , y el empírico es la frecuencia relativa del mismo evento. Del teorema de Bernoulli sigue
, y el empírico es la frecuencia relativa del mismo evento. Del teorema de Bernoulli sigue
 ,
,
 (10.20)
(10.20)
esos. con gran  probabilidad
probabilidad  y frecuencia relativa del evento
y frecuencia relativa del evento  .
.  un poco diferente del otro. Ya, se sigue la viabilidad de usar la función de distribución de muestras empíricas para una representación aproximada de la función teórica (integral) de la distribución de la población general.
un poco diferente del otro. Ya, se sigue la viabilidad de usar la función de distribución de muestras empíricas para una representación aproximada de la función teórica (integral) de la distribución de la población general.
Función  y
y  poseer las mismas propiedades. Esto se desprende de la definición de la función.
poseer las mismas propiedades. Esto se desprende de la definición de la función. 
Propiedades  :
:

Ejemplo 10.4. Construye una función empírica en esta distribución de la muestra:
|
Opciones | |||
|
Frecuencia |


Decisión: Encuentra el tamaño de la muestra. nORTE.=
12 + 18 + 30 \u003d 60. La opción más pequeña  , por eso,
, por eso,  por
por  . Valor
. Valor  , a saber
, a saber  observado 12 veces, por lo tanto:
observado 12 veces, por lo tanto:
 =
= por
por  .
.
Valor x.<
10, a saber  y
y  12 + 18 \u003d 30 veces se observaron, por lo tanto,
12 + 18 \u003d 30 veces se observaron, por lo tanto,  =
=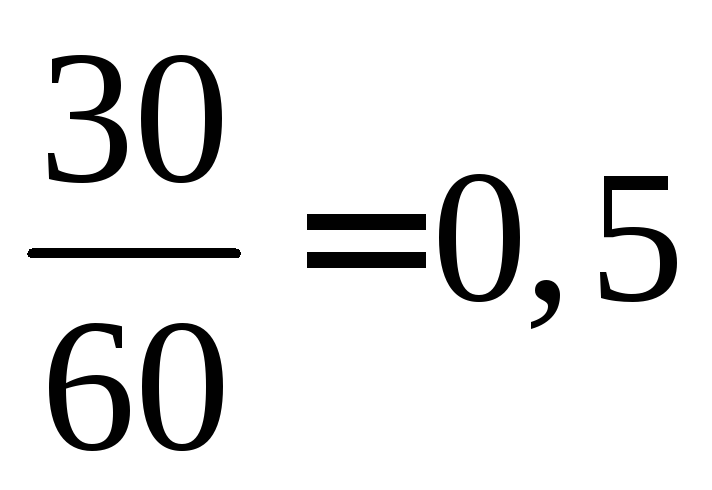 por
por  . Para
. Para 
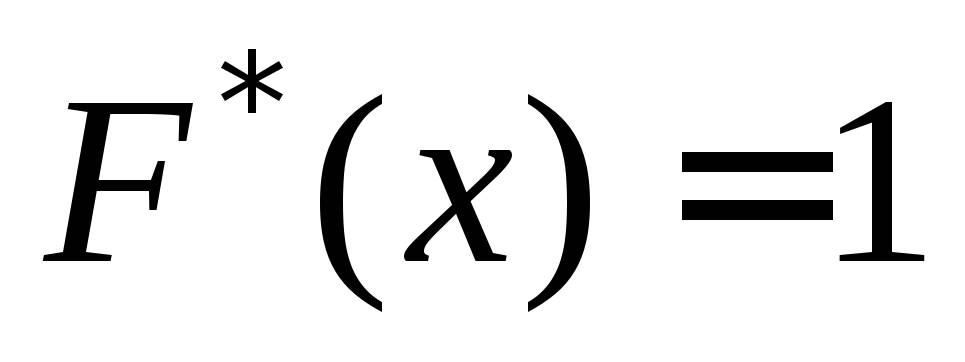 .
.
La función de distribución empírica deseada:
 =
=
Calendario  presentado en la fig. 10.2
presentado en la fig. 10.2
R  iP. 10.2
iP. 10.2
Preguntas de control
1. ¿Cuáles son las tareas principales resuelven estadísticas matemáticas? 2. Agregado general y selectivo? 3. Dar la definición de la muestra. 4. ¿Qué muestras se llama representante? 5. Errores representativos. 6. Formas básicas de formar muestreo. 7. Los conceptos de frecuencia, frecuencia relativa. 8. El concepto de la serie estadística. 9. Registre la fórmula STARGEZ. 10. Palabra los conceptos de muestreo, medianos y mods. 11. Frecuencias de polígonos, histograma. 12. El concepto de una estimación puntual del agregado selectivo. 13. Estimación de puntos desplazados y increíbles. 14. Palabra el concepto de medio selectivo. 15. Palabra el concepto de dispersión selectiva. 16. Palabra el concepto de desviación de RMS selectiva. 17. Palabra el concepto de coeficiente de variación selectiva. 18. Palabra el concepto de medio selectivo geométrico.
