Charakterystyka dystrybucji dwumianowej. Rozkład dwumianowy
Oczywiście, przy obliczaniu skumulowanej funkcji dystrybucji należy stosować przez wspomniany spoiwo i dystrybucję beta. Ta metoda jest świadomie lepsza niż natychmiastowe sumowanie, gdy N\u003e 10.
W klasycznych podręcznikach statystyk, formuły oparte na limitach twierdzeń (takich jak formuła Moava Laplace) są często zalecane do uzyskania wartości dwumianowych. Należy zauważyć że z czystym punktem widzenia Wartość tych twierdzeń znajduje się w pobliżu zera, zwłaszcza teraz, gdy prawie każdy stół jest potężnym komputerem. Główną wadą powyższych przybliżeń jest ich całkowicie niewystarczająca dokładność w wartości n wartości typowych dla większości aplikacji. Nie mniej wadą jest brak jakichkolwiek jasnych zaleceń dotyczących zastosowania jednego lub innego przybliżenia (tylko sformułowanie asymptotyczne podano w standardowych tekstach, nie towarzyszy im szacunki dokładności, a zatem nie są bardzo przydatne). Powiedziałbym, że oba formuły są odpowiednie tylko dla n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Nie uważam tutaj zadania poszukiwania ilościowego: jest trywialny dla dyskretnych dystrybucji, aw tych zadaniach, w których powstają takie dystrybucje, zwykle nie ma znaczenia. Jeśli Quantil nadal będzie potrzebny, zalecam przeformułowanie zadania do pracy z wartościami P (obserwowane substancje). Oto przykład: Przy wdrażaniu niektórych bieżących algorytmów na każdym kroku jest wymagana do sprawdzenia hipotezy statystycznej o zmiennej losowej binomicznej. Zgodnie z klasycznym podejściem na każdym kroku konieczne jest obliczenie statystyk kryterium i porównania jego wartości z granicą zestawu krytycznego. Ponieważ jednak algorytm jest uszkodzony, konieczne jest określenie granicy zestawu krytycznego za każdym razem (przecież, z kroku do kroku, zmiany głośności próbki), że nie ma integralnie zwiększa koszty czasu. Nowoczesne podejście zaleca przetwarzanie zaobserwowanego znaczenia i porównać go z ufnym prawdopodobieństwem, oszczędzając w poszukiwaniu ilościowego.
Dlatego w poniższych kategoriach nie ma obliczenia funkcji odwrotnej, zamiast funkcji rev_binomialdf jest obliczany, co oblicza prawdopodobieństwo P OKSPORTU w oddzielnym badaniu w określonej ilości testów N, liczba sukcesu M i prawdopodobieństwo z tych sukcesów. Wykorzystuje wyżej wymienioną wiązanie między dystrybucją dwumianową a beta.
W rzeczywistości ta funkcja pozwala uzyskać granice interwałów zaufania. W rzeczywistości zakładamy, że w testach binomicznych otrzymaliśmy sukces. Jak wiadomo, lewy limit dwustronnego przedziału ufności dla parametru P z poziomem ufności wynosi 0, jeśli m \u003d 0 i dla roztworu równania  . Podobnie, prawa granica wynosi 1, jeśli m \u003d N i do roztworu równania
. Podobnie, prawa granica wynosi 1, jeśli m \u003d N i do roztworu równania  . Stąd wynika, że \u200b\u200bszukanie lewej granicy musimy rozwiązać w stosunku do równania
. Stąd wynika, że \u200b\u200bszukanie lewej granicy musimy rozwiązać w stosunku do równania  i znaleźć właściwe - równanie
i znaleźć właściwe - równanie  . Są one rozwiązane w funkcjach binom_leftci i binom_rightci, które zwracają górne i dolne granice odpowiednio przedziału zaufania dwukierunkowego.
. Są one rozwiązane w funkcjach binom_leftci i binom_rightci, które zwracają górne i dolne granice odpowiednio przedziału zaufania dwukierunkowego.
Chcę zauważyć, że jeśli nie potrzebujesz absolutnie niesamowitej dokładności, a następnie z dość dużym n, możliwe jest skorzystanie z następującego przybliżenia [B.L. Van Der Warden, statystyki matematyczne. M: IL, 1960, Ch. 2 sekundy. 7]:  gdzie g jest ilościowym dystrybucją normalną. Wartość tego przybliżenia jest to, że istnieją bardzo proste przybliżenia, co pozwala obliczyć ilościowy rozkład normalny (patrz tekst na obliczaniu rozkładu normalnego i odpowiedniej sekcji tej książki referencyjnej). W mojej praktyce (głównie, z N\u003e 100), to przybliżenie dało około 3-4 znaków, które zwykle jest wystarczająco dość.
gdzie g jest ilościowym dystrybucją normalną. Wartość tego przybliżenia jest to, że istnieją bardzo proste przybliżenia, co pozwala obliczyć ilościowy rozkład normalny (patrz tekst na obliczaniu rozkładu normalnego i odpowiedniej sekcji tej książki referencyjnej). W mojej praktyce (głównie, z N\u003e 100), to przybliżenie dało około 3-4 znaków, które zwykle jest wystarczająco dość.
W przypadku obliczeń przy użyciu następujących kodów, pliki betadf.h będą wymagane, betadf.cpp (patrz sekcja na dystrybucji beta), a także loggamma.h, loggamma.cpp (patrz załącznik A). Możesz także zobaczyć przykład korzystania z funkcji.
Plik binomialdf.h.
| #ifndef __binomial_h__ #include "betadf.h" podwójny binomialdf (podwójne próby, podwójne sukcesy, podwójne p); / * * Niech będzie "próby" niezależnych obserwacji * z prawdopodobieństwem "p" sukcesu w każdym. * Prawdopodobieństwo b (sukcesy | próby, p) oblicza się, że numer * sukces jest zawierany między 0 a "sukcesami" (włącznie). * / Podwójna rev_binomialdf (podwójne próby, podwójne sukcesy, podwójne y); / * * Załóżmy, że prawdopodobieństwo pojawienia się przynajmniej mnótwej sukcesu * w testach badań programu Bernoulliego. Funkcja znajduje prawdopodobieństwo p * sukces w osobnym teście. * * W obliczeniach stosuje się następujący stosunek * * 1 - p \u003d rev_beta (badania-sukcesy | sukcesy + 1, y). * / Podwójne binom_leftci (podwójne próby, podwójne sukcesy, podwójny poziom); / * Niech będzie "próby" niezależnych obserwacji * z prawdopodobieństwem "p" sukcesu w każdym *, a liczba sukcesu jest "sukcesy". * Lewy limit dwustronnego przedziału ufności * jest obliczany z poziomem poziomu istotności. * / Podwójne binom_rightCI (podwójne n, podwójne sukcesy, podwójny poziom); / * Niech będzie "próby" niezależnych obserwacji * z prawdopodobieństwem "p" sukcesu w każdym *, a liczba sukcesu jest "sukcesy". * Prawidłowa granica dwustronnego przedziału ufności * jest obliczana z poziomem ważności. * / #endif / * kończy #ifndef __binomial_h__ * / |
Plik binomialdf.cpp.
| / *********************************************** ********** / / * Rozkład dwumianowy * / / ******************************** *************************** / #Zawierać. |
Teoria prawdopodobieństwa jest niewidocznie obecna w naszym życiu. Nie zwracamy na to uwagi, ale każde wydarzenie w naszym życiu ma jedno prawdopodobieństwo. Biorąc pod uwagę ogromną liczbę opcji rozwoju wydarzeń, konieczne staje się określenie najbardziej prawdopodobnych i najmniej prawdopodobnych z nich. Wygodne jest graficznie przeanalizowanie takich danych probabilistycznych. W tym możemy pomóc dystrybucji. Binomial jest jednym z najłatwiejszych i najbardziej dokładnych.
Przed przejściem bezpośrednio do matematyki i teorii prawdopodobieństwa radzimy sobie z tymi, którzy najpierw wymyślili taki rodzaj dystrybucji i jaka jest historia rozwoju aparatu matematycznego dla tej koncepcji.
Historia
Koncepcja prawdopodobieństwa jest znana od czasów starożytnych. Jednak starożytni matematycy nie przywiązują się do niego szczególnie znaczenia i byli w stanie położyć tylko podstawy teorii, co następnie stało się teorią prawdopodobieństwa. Stworzyli niektóre metody kombinatoryczne, które zdecydowanie pomogły ci, którzy później stworzyli i opracowali teorię samą.
W drugiej połowie XVII wieku rozpoczęła się tworzenie podstawowych koncepcji i metod teorii prawdopodobieństwa. Wprowadzono zmienne losowe, metody obliczania prawdopodobieństwa prostego i niektórych złożonych niezależnych i zależnych wydarzeń. Dyktowane takie zainteresowanie wartościami losowymi i prawdopodobieństwem było hazard: Każda osoba chciała wiedzieć, jakie są szanse, że musiał wygrać w grze.
Następnym krokiem była aplikacja w teorii prawdopodobieństwa metod analizy matematycznej. Został on zaangażowany w wybitnych matematyków, takich jak Laplace, Gauss, Poisson i Bernoulli. To byli, którzy zaawansowali ten region matematyki na nowy poziom. Był James Bernoulli, który otworzył binomian prawo dystrybucji. Nawiasem mówiąc, gdy później się dowiemy, na podstawie tego odkrycia, jeszcze kilka, co pozwoliło na stworzenie prawa dystrybucji normalnej i wielu innych innych.
Teraz, zanim zaczniesz opisać dystrybucję binomicznej, jesteśmy trochę odświeżającym w pamięci koncepcji teorii prawdopodobieństwa, prawdopodobnie już zapomniane ze szkolnej ławki.
Podstawy teorii prawdopodobieństwa
Rozważymy takie systemy w wyniku czego możliwe są tylko dwa egzodus: "sukces" i "nie sukces". Łatwo jest zrozumieć na przykładzie: rzucamy monetą, zanikając, co wypadnie pośpiech. Prawdopodobieństwo każdego z możliwych zdarzeń (upadnie pośpiech - "sukces", orzeł spadnie - "nie sukces") jest równy 50 procent z idealną równowagą monetą i brakiem innych czynników, które mogą mieć wpływ eksperyment.
To było najłatwiejsze wydarzenie. Istnieją jednak również złożone systemy, w których przeprowadzane są kolejne działania, a prawdopodobieństwa wyników tych działań będą różne. Na przykład, rozważ taki system: w pudełku, którego zawartość, której nie możemy zobaczyć, leżą sześć zupełnie identycznych kulek, trzy pary kolorów niebieskich, czerwonych i białych kolorów. Musimy uzyskać losowe kilka piłek. W związku z tym, wyciągając jedną z białej kule, zmniejszamy prawdopodobieństwo, że biała piłka będzie do nas przyjść. Dzieje się tak, ponieważ liczba obiektów w systemie zmienia się.
W następnej sekcji uważamy bardziej złożone koncepcje matematyczne, ściśle zastosowane do tego, co oznaczają słowa "normalna dystrybucja", "dystrybucja dwumiana" i tym podobne.

Elementy statystyki matematycznej
W statystykach, który jest jednym z zastosowań teorii prawdopodobieństwa, istnieje wiele przykładów, gdy dane do analizy nie są wyraźnie. To znaczy, nie w liczbie numerycznych, ale w formie podziału na funkcje, na przykład przez seks. W celu zastosowania aparatu matematycznego do takich danych i dokonuje wniosków z uzyskanych wyników, wymagane są dane źródłowe w formacie numerycznym. Z reguły, w celu wdrożenia tego, pozytywny wynik przypisuje wartość 1 i ujemny - 0. Zatem otrzymujemy dane statystyczne, które można analizować przy użyciu metod matematycznych.
Kolejnym krokiem w zrozumieniu, jaki rozkład binomiczny zmiennej losowej określa dyspersję losowej zmiennej i oczekiwań matematycznych. Porozmawiaj z tym w następnej sekcji.

Wartość oczekiwana
W rzeczywistości łatwo jest zrozumieć, jakie oczekiwania matematyczne jest łatwe. Rozważmy system, w którym istnieje wiele różnych wydarzeń z różnymi prawdopodobieństwami. Oczekiwanie matematyczne zostaną nazwane wartością równą ilością wartości tych zdarzeń (a formularz matematyczny rozmawialiśmy w przeszłości) w prawdopodobieństwie ich wdrożenia.
Matematyczne oczekiwania dystrybucji dwumianowej jest obliczana przez ten sam schemat: podejmujemy wartość zmiennej losowej, pomnóż ją na prawdopodobieństwo pozytywnego wyniku, a następnie podsumowujemy dane uzyskane dla wszystkich wartości. Jest to bardzo wygodne, aby wyświetlić te dane graficznie - lepiej jest, aby różnica między oczekiwaniami matematycznymi o różnych ilościach jest postrzegana.
W następnej sekcji powiemy ci trochę o innej koncepcji - dyspersji zmiennej losowej. Jest również ściśle związany z taką koncepcją jako dystrybucję prawdopodobieństwa binomicznego i jest jego charakterystyką.

Dyspersja dystrybucji dwumianowej
Ta wartość jest ściśle związana z poprzednią, a także charakteryzuje dystrybucję danych statystycznych. Jest to przeciętny kwadrat odchyleń wartości z ich oczekiwań matematycznych. Oznacza to, że dyspersja zmiennej losowej jest sumą kwadratów różnic między wartością zmiennej losowej a jego oczekiwaniami matematycznymi, pomnożone prawdopodobieństwem tego wydarzenia.
Ogólnie rzecz biorąc, to wszystko, co musimy wiedzieć o dyspersji, aby zrozumieć, jaki jest dwumianowy dystrybucja prawdopodobieństw. Teraz udajmy się bezpośrednio z naszym głównym tematem. Mianowicie, co leży dla tego w wyglądzie raczej złożonego frazy "prawnicę dwumianową".

Rozkład dwumianowy
Dowiedzmy się na początku, dlaczego jest to dystrybucja dwumiana. Pochodzi ze słowa "bin". Może słyszałeś o binomie Newtona - taka formuła, z którą można rozłożyć sumę dwóch dowolnych liczb A i B do dowolnego stopnia negatywnego n.
Jak zapewne odgadłeś, formuła binoma Newton i formuła dystrybucji dwumianowej jest prawie tym samym formulem. Wyjątkiem jest tylko, że druga jest stosowana do określonych ilości, a pierwsza jest tylko wspólnym narzędziem matematycznym, którego aplikacje mogą być inne w praktyce.
Wzory dystrybucyjne.
Funkcja dystrybucji dwumianowej może być rejestrowana jako suma następujących członków:
(N! / (N - K)! K!) * P K * Q N-K
Tutaj n jest liczbą niezależnych przypadkowych eksperymentów, liczba udanych wyników, Q - liczba nieudanych wyników, K jest numerem eksperymentu (może przyjmować wartości od 0 do N),! - Wyznaczenie czynności, takiego funkcji, której wartość jest równa produktowi wszystkich numerów idzie do niego (na przykład dla numeru 4: 4! \u003d 1 * 2 * 3 * 4 \u003d 24).
Ponadto funkcja dystrybucji dwumianowej może być rejestrowana jako niekompletna funkcja beta. Jest to jednak bardziej złożona definicja, która jest używana tylko podczas rozwiązywania złożonych problemów statystycznych.
Dystrybucja dwumianowa, której przykłady, których uważaliśmy powyżej, są jednym z najprostszych rodzajów dystrybucji w teorii prawdopodobieństwa. Istnieje również normalny rozkład, który jest jednym z rodzajów binomicznych. Jest on najczęściej używany, a najbardziej w obliczeniach. Istnieje również dystrybucja Bernoulliego, dystrybucji Poissona, dystrybucji warunkowej. Wszystkie charakteryzują obszary graficznie o prawdopodobieństwie jednego lub innego procesu w różnych warunkach.
W następnej sekcji rozważ aspekty dotyczące stosowania tego aparatu matematycznego w prawdziwym życiu. Na pierwszy rzut oka wydaje się, że jest to kolejna rzecz matematyczna, która jak zwykle nie znajduje zastosowań w prawdziwym życiu, a w ogóle nie jest potrzebny przez nikogo, z wyjątkiem samych matematyków. Jednak tak nie jest. W końcu wszystkie rodzaje dystrybucji i ich reprezentacje graficzne zostały stworzone wyłącznie w celach praktycznych, a nie jako kaprysy naukowców.

Podanie
Oczywiście najważniejszym zastosowaniem dystrybucji znajduje się w statystykach, ponieważ istnieje kompleksowa analiza zestawu danych. Jak pokazuje, że praktyka, bardzo wiele tablic danych ma takie same dystrybucje ilości: krytyczne obszary bardzo niskich i bardzo wysokich wartości, z reguły zawierają mniej elementów niż średnie wartości.
Analiza dużych tablic danych jest wymagana nie tylko w statystykach. Jest niezbędny, na przykład w chemii fizycznej. W tej nauce służy do określenia wielu wartości związanych z losowymi oscylacjami i ruchami atomów i cząsteczek.
W następnej sekcji zajmiemy się, jak ważne jest wykorzystanie takich koncepcji statystycznych jako binomian dystrybucja zmiennej losowej w życiu codziennym dla nas z tobą.

Po co mi to?
Wielu zadaje się takim pytaniem, jeśli chodzi o matematykę. A przy okazji matematyka nie jest na próżno zwanym królową nauki. Jest podstawą fizyki, chemii, biologii, ekonomii, a w każdym z tych nauk stosuje się w tym dowolną dystrybucję: czy jest to dyskretny dystrybucja dwumianowa, czy normalna, bez względu na to. A jeśli będziemy lepszy do świata na całym świecie, zobaczymy, że matematyka jest stosowana wszędzie: w życiu codziennym, w pracy, a nawet stosunki człowieka można przedłożyć w formie danych statystycznych i analizować ich analizę (tak, przez Droga, tworzą ci, którzy pracują w specjalnych organizacjach zaangażowanych w zbieranie informacji).
Teraz porozmawiajmy trochę o tym, co robić, jeśli musisz wiedzieć o tym temacie więcej niż to, co przedstawiliśmy w tym artykule.
Te informacje, które daliśmy w tym artykule, są dalekie od zakończenia. Istnieje wiele niuansów dotyczących tego, co forma może wziąć dystrybucję. Dystrybucja dwumianowa, jak już odkryliśmy, jest jednym z głównych gatunków, na których opierają się wszystkie statystyki matematyczne i teoria prawdopodobieństwa.
Jeśli stało się ciekawe, lub w związku z pracą, musisz wiedzieć o tym temacie znacznie więcej, będziesz musiał zbadać wyspecjalizowaną literaturę. Zacznij wynika z uniwersyteckiego przebiegu analizy matematycznej i udostępnić tam do sekcji teorii prawdopodobieństwa. Znajomość rzędów będzie również przydatna, ponieważ dwumian dystrybucja prawdopodobieństw jest niczym więcej niż serią kolejnych członków.
Wniosek
Przed zakończeniem artykułu chcielibyśmy powiedzieć kolejną ciekawą rzecz. Dotyczy tematu naszego artykułu i całej matematyki jako całości.
Wielu ludzi twierdzi, że matematyka jest bezużyteczna nauka i nic z tego, co miały miejsce w szkole, nie byli przydatni. Ale wiedza nigdy nie jest zbędna, a jeśli coś nie jest przydatne w życiu, oznacza to, że po prostu tego nie pamiętasz. Jeśli masz wiedzę, mogą ci pomóc, ale jeśli nie, nie możesz czekać na pomoc od nich.
Tak więc uważaliśmy za koncepcję dystrybucji dwumianowej i wszystkich powiązanych definicji i rozmawiało o tym, jak stosuje się do naszego życia z tobą.
Rozważ realizację schematu Bernoulliego, tj. Dostępna jest seria wielokrotnych testów niezależnych, w każdym przypadku, z której to wydarzenie ma to samo prawdopodobieństwo, które nie zależą od numeru testowego. A dla każdego testu znajdują się tylko dwa przerwy:
1) wydarzenie A - sukces;
2) Wydarzenie - niepowodzenie
ze stałymi prawdopodobieństwami
Wprowadzamy dyskretną ilość losową X - "liczba zdarzeń i p. Testy "i znajdź prawo dystrybucji tej zmiennej losowej. X może tworzyć wartości
Prawdopodobieństwo ![]() że zmienna losowa weźmie wartość x K. Znajduje się przez Formułę Bernoulliego
że zmienna losowa weźmie wartość x K. Znajduje się przez Formułę Bernoulliego
Nazywana jest prawo dystrybucji dyskretnej zmiennej losowej określonej przez wzoru Bernoulliego (1) prawo dystrybucji dwumianowej. Stały p. i r. (q \u003d 1-p)nazywane są w formiecie (1) parametry dystrybucji dwumianowej.
Nazwa "Dystrybucja dwumianowa" wiąże się z faktem, że prawa strona w równości (1) jest członkiem ogólnym dekompozycji binoma Newtona, tj.
(2)
I od tego czasu p + Q \u003d 1, prawa strona równości (2) jest równa 1
To znaczy, że
 (4)
(4)
W równości (3) pierwszego członka p N. Właściwa część oznacza prawdopodobieństwo p. Wydarzenia testowe i nigdy nie pojawią się, drugi członek ![]() prawdopodobieństwo, że wydarzenie pojawi się raz, trzeci Dick jest prawdopodobieństwem, że wydarzenie pojawi się dwa razy i wreszcie ostatni członek p. - Prawdopodobieństwo, że wydarzenie wydaje się dokładnie p. czas.
prawdopodobieństwo, że wydarzenie pojawi się raz, trzeci Dick jest prawdopodobieństwem, że wydarzenie pojawi się dwa razy i wreszcie ostatni członek p. - Prawdopodobieństwo, że wydarzenie wydaje się dokładnie p. czas.
Prawo dystrybucji dwumianowej dyskretnej zmiennej losowej jest reprezentowany jako tabela:
| H. | 0 | 1 | … | k. | … | n. |
| R. | p N. | … | … | p. |
Główne cechy numeryczne dystrybucji dwumianowej:
1) oczekiwanie matematyczne ![]() (5)
(5)
2) Dyspersja ![]() (6)
(6)
3) wtórne odchylenie kwadratowe ![]() (7)
(7)
4) Najbardziej odpowiednia liczba zdarzeń k 0. - To jest numer z określonym p. odpowiada maksymalnemu prawdopodobieństwu dwumianowym
Na określony p. i r. Ta liczba jest określona przez nierówności
![]() (8)
(8)
jeśli numer pR + R. nie jest wtedy całkowitą k 0. Równie cała część tego numeru, jeśli pR + R. - Integer, wtedy k 0. Ma dwa znaczenia
Binomialne prawo dystrybucji prawdopodobieństwa stosuje się w teorii strzelania, teoretycznie i praktyki statystycznej kontroli jakości produktu, w teorii usług masowych, w teorii niezawodności itp. Ustawa ta może być stosowana we wszystkich przypadkach, gdy istnieje sekwencja niezależnych testów.
Przykład 1:Testy jakości jest ustalane, że z każdego 100 urządzeń nie mają średniego wad 90 sztuk. Dokonaj binomiczanego prawa dystrybucji prawdopodobieństwa liczby wysokiej jakości urządzeń z nabytych w losowej 4.
Decyzja:Wydarzenie A - którego wygląd jest sprawdzany przez to - "nabyte na jakość losowej urządzenia". W warunkach problemu główne parametry dystrybucji dwumianowej:
Wartość losowa X jest liczbą wysokiej jakości urządzeń wykonanych z 4, co oznacza, że \u200b\u200bwartości X-próba prawdopodobieństwa wartości X według wzoru (1):

Tak więc wartość rozkładu ilości X jest liczba wysokiej jakości instrumentów wykonanych z 4:
| H. | 0 | 1 | 2 | 3 | 4 |
| R. | 0,0001 | 0,0036 | 0,0486 | 0,2916 | 0,6561 |
Aby sprawdzić poprawność konstruktu dystrybucyjnego, sprawdź, dlaczego suma prawdopodobieństw jest równa
Odpowiedź:Prawo dystrybucji
| H. | 0 | 1 | 2 | 3 | 4 |
| R. | 0,0001 | 0,0036 | 0,0486 | 0,2916 | 0,6561 |
Przykład 2:Metoda obróbki stosowana prowadzi do odzyskiwania w 95% przypadków. Pięciu pacjentów zastosowało tę metodę. Znajdź najbardziej numeryczne cechy zmiennej losowej X - liczba odzyskanych od 5 pacjentów wykorzystała tę metodę.
Rozważmy rozkład binomiczny, obliczymy jego oczekiwania matematyczne, dyspersję, mody. Korzystanie z funkcji MS Excel Binomesp () konstruujemy wykresy funkcji dystrybucji i gęstości prawdopodobieństwa. Będziemy ocenić parametr dystrybucji P, oczekiwanie matematyczne dystrybucji i odchylenia standardowego. Rozważymy również dystrybucję Bernoulli.
Definicja . Pozwól im się odbyć N. Testy, w każdym z których mogą wystąpić tylko 2 zdarzenia: zdarzenie "sukces" z prawdopodobieństwem P. lub wydarzenie "niepowodzenie" z prawdopodobieństwem P. \u003d 1 p (tak zwany Schemat Bernoulli, Bernoulli. próby.).
Prawdopodobieństwo uzyskania dokładnie X. Sukcesy w nich. N. Testy są równe:
Liczba sukcesu w próbce X. jest losową wartością, która ma Rozkład dwumianowy (pol. Dwumianowy Dystrybucja) P. i N. – są parametrami tej dystrybucji.
Przypomnijmy to do użytku Schematy Bernoulli. i odpowiednio Rozkład dwumianowy Należy zakończyć następujące warunki:
- każdy test musi mieć dokładnie dwa wyniki, warunkowo określane jako "sukces" i "porażkę".
- wynik każdego testu nie powinien zależeć od wyników poprzednich testów (niezależność testowa).
- prawdopodobieństwo sukcesu P. Musi być stała dla wszystkich testów.
Dystrybucja binomiczna w MS Excel
W MS Excel, zaczynając w 2010 roku Istnieje funkcja binom (), nazwa angielskiego - binom.dist (), co pozwala obliczyć prawdopodobieństwo, że w próbce będzie gładka H. "Sukcesy" (tj. Funkcja gęstości prawdopodobieństwa p (x), zobacz formułę powyżej), i Integralna funkcja dystrybucji (Prawdopodobieństwo, że w próbce będzie X. lub mniej "sukces", w tym 0).
Przed MS Excel 2010 Excel miał funkcję binomap (), która również pozwala nam obliczyć Funkcja dystrybucyjna i gęstości prawdopodobieństwa P (x). Binomap () pozostaje w MS Excel 2010 za zgodność.
Przykładowy plik pokazuje wykresy Dystrybucja prawdopodobieństwa i .

Rozkład dwumianowy Ma notacji B. ( N. ; P.) .
Uwaga : Do budynku. Integralna funkcja dystrybucji Idealny diagram dopasowania Harmonogram dla Dystrybucja dystrybucji – Histogram z grupowaniem . Przeczytaj więcej o wykresach budowlanych Przeczytaj artykuł Główne typy diagramów.
Uwaga : Aby ułatwić pisanie formuły w przykładowym pliku utworzone nazwy parametrów Rozkład dwumianowy : N i str.

Plik przykładowy zapewnia różne obliczenia prawdopodobieństwa przy użyciu funkcji MS Excel:
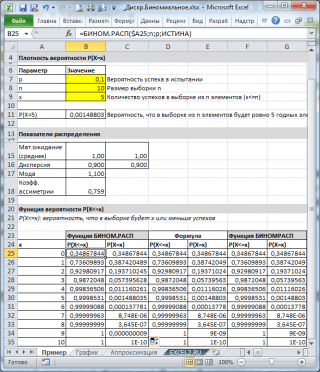
Jak widać na powyższym zdjęciu, zakłada się, że:
- W nieskończonym zestawie, z którego wykonana jest próbka, zawiera 10% (lub 0,1) odpowiednich elementów (parametr P. , trzeci argument funkcji \u003d bin.rasp ())
- Aby obliczyć prawdopodobieństwo, że w próbce 10 elementów (parametr N. Drugi argument funkcji) będzie dokładnie 5 odpowiednimi elementami (pierwszy argument), musisz nagrywać formułę: \u003d Binomasp (5; 10; 0,1; kłamstwa)
- Ostatni, czwarty element, set \u003d false, tj. Zwraca wartość funkcji Dystrybucja dystrybucji .
Jeśli wartość czwartego argumentu \u003d prawda, funkcja bin () zwraca wartość Integralna funkcja dystrybucji lub po prostu Funkcja dystrybucyjna . W tym przypadku możliwe jest obliczenie prawdopodobieństwa, że \u200b\u200bw próbce liczba odpowiednich elementów będzie od określonego zakresu, na przykład 2 lub mniej (w tym 0).
Aby to zrobić, musisz zapisać formułę: \u003d Binom.rp (2; 10; 0,1; prawda)
Uwaga : Z wartością nenetową X ,. Na przykład następujące wzory zwrócą tę samą wartość: \u003d Bin. 2 ; 10; 0,1; PRAWDZIWE) \u003d Bin. 2,9 ; 10; 0,1; PRAWDZIWE)
Uwaga : W przykładowym pliku gęstości prawdopodobieństwa i Funkcja dystrybucyjna Obliczono również za pomocą definicji i funkcji NUMMBB ().
Wskaźniki dystrybucji
W Przykładowy plik na przykładku Są formuły do \u200b\u200bobliczania pewnych wskaźników dystrybucji:
- \u003d n * p;
- (kwadratowy odchylenie standardowe) \u003d n * p * (1-p);
- \u003d (n + 1) * p;
- \u003d (1-2 * p) * root (N * p * (1-P)).
Wycofać formułę oczekiwanie matematyczne Rozkład dwumianowy Za pomocą Schemat Bernoulli. .
Z definicji, losowa wartość x w Schemat Bernoulli. (Zmienna losowa Bernoulli) ma Funkcja dystrybucyjna :

Ta dystrybucja jest nazywana Dystrybucja Bernoulli. .
Uwaga : Dystrybucja Bernoulli. - prywatny przypadek Rozkład dwumianowy z parametrem n \u003d 1.
Wygenerujmy 3 tablicę 100 liczb o różnych prawdopodobieństwach sukcesu: 0,1; 0,5 i 0,9. Aby to zrobić w oknie Generacja liczb losowych Ustaw poniższe parametry dla każdego prawdopodobieństwa P:

Uwaga : Jeśli ustawisz opcję Losowa dyspersja ( Losowe nasienie) Możesz wybrać określony losowy zestaw liczb generowanych. Na przykład, poprzez ustawienie tej opcji \u003d 25, można go wygenerować na różnych komputerach, takie same zestawy liczb losowych (chyba że oczywiście inne parametry dystrybucyjne są zbiegły). Wartość opcji może podjąć całe wartości od 1 do 32 767. Nazwa opcji Losowa dyspersja może pomylić. Lepiej byłoby to przetłumaczyć Ustaw numer z liczbami losowymi .
W rezultacie będziemy mieć 3 kolumny 100 liczb, na podstawie których można, na przykład ocenić prawdopodobieństwo sukcesu. P. Według wzoru: Liczba sukcesu / 100 (cm. Plik przykładowy liść generationBurly).
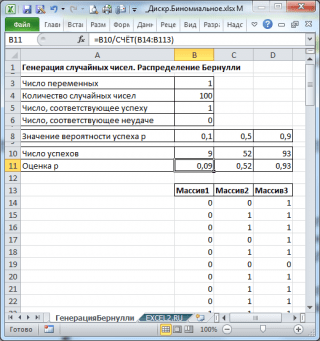
Uwaga : Dla Dystrybucja Bernoulli. Za pomocą p \u003d 0,5 można użyć formuły \u003d racjonowanie (0; 1), które odpowiada.
Generacja liczb losowych. Rozkład dwumianowy
Przypuśćmy, że w próbce odkryto 7 wadliwych produktów. Oznacza to, że sytuacja jest "bardzo prawdopodobna", że udział się udział wadliwych produktów P. który jest charakterystyką naszego procesu produkcyjnego. Chociaż ta sytuacja jest "bardzo prawdopodobna", ale istnieje szansa (ryzyko alfa, błąd 1 rodzaju, "fałszywy alarm"), który jest nadal P. Pozostał niezmieniony, a zwiększona liczba wadliwych produktów wynika z losowa próbkowania.
Jak widać na rysunku poniżej, 7 jest liczbą wadliwych produktów, które są dopuszczalne dla procesu z p \u003d 0,21 o tej samej wartości Alfa . Służy to jako ilustracja, gdy wartość progowa wadliwych produktów jest przekroczona w próbce, P. "Najprawdopodobniej" wzrosła. Wyrażenie "najprawdopodobniej" oznacza, że \u200b\u200bistnieje tylko 10% prawdopodobieństwo (100% -90%), że odchylenie udziału wadliwych produktów powyżej progu jest spowodowane tylko przyczynami.

W ten sposób przekroczenie progu numer wadliwych produktów w próbce może być sygnałem, że proces jest zdenerwowany i zaczął produkować B o Spędził procent wadliwych produktów.
Uwaga : Przed MS Excel 2010 w Excelu była funkcja CRTBIN () (), która jest równoważna z binomami (). Cretebin () pozostaje w MS Excel 2010 i więcej o zgodność.
Komunikacja dystrybucji dwumianowej z innymi dystrybucjami
Jeśli parametr. N. Rozkład dwumianowy ma tendencję do nieskończoności i P. ma tendencję do 0, a następnie w tym przypadku Rozkład dwumianowy Może być przybliżony. Warunki można sformułować, gdy przybliżenie Dystrybucja Poissona Działa dobrze:
- P. (mniej P. i więcej N. , najbliższe przybliżenie);
- P. >0,9 (biorąc pod uwagę, że P. =1- P. , Obliczenia w tym przypadku należy wykonać P. (ale H. Trzeba zastąpić N. - X.). W związku z tym P. i więcej N. , przybliżenie jest bardziej dokładne).
Przy 0,110. Rozkład dwumianowy Możesz przybliżyć.
Z kolei, Rozkład dwumianowy może służyć jako dobre przybliżenie, gdy rozmiar całości N Dystrybucja hipergeometryczna Znacznie więcej próbek próbkowania N (tj. N \u003e\u003e N lub N / N. więcej o podłączeniu powyższych dystrybucji, można przeczytać w artykule. Istnieją również przykłady przybliżenia, a warunki wyjaśniono, gdy jest to możliwe, co jest możliwe precyzja.
Rada : Na innym dystrybucji MS Excel można znaleźć w artykule.
Rozdział 7.
Szczególne prawa dystrybucji zmiennych losowych
Rodzaje praw dystrybucji dyskretnych zmiennych losowych
Niech dyskretna wartość losowa może podjąć wartości h. 1 , h. 2 , …, x N..... Prawdopodobieństwa tych wartości można obliczyć według różnych formuł, na przykład, używając podstawowych twierdzeń teorii prawdopodobieństwa, wzorów Bernoulli lub przez inne wzory. Dla niektórych z tych formuł, prawo dystrybucji ma swoją nazwę.
Najczęstszymi przepisami dystrybucji dyskretnej wariancji losowej są dwumianowe, geometryczne, hipergeometryczne, Prawa Dystrybucyjne Poissona.
Prawo dystrybucji dwumianowej
Niech zostanie wyprodukowany n. Niezależne testy, w każdym z których może pojawić się zdarzenie lub nie pojawiają się ALE. Prawdopodobieństwo tego zdarzenia w każdym badaniu jest stałe, nie zależy od numeru testowego i równego r.=R.(ALE). Stąd prawdopodobieństwo braku wydarzenia ALE W każdym badaniu jest również stały i równy p.=1–r.. Rozważyć losową kwotę H. równy liczbie wydarzeń ALE w n. Testy. Oczywiście wartości tej wartości są równe
h. 1 \u003d 0 - wydarzenie ALE w n. Testy nie pojawiły się;
h. 2 \u003d 1 - wydarzenie ALE w n. Testy pojawiły się raz;
h. 3 \u003d 2 - wydarzenie ALE w n. Testy pojawiły się dwa razy;
…………………………………………………………..
x N. +1 = n. - Event. ALE w n. Pojawiły się testy. n. czas.
Prawdopodobieństwa tych wartości można obliczyć za pomocą wzoru Bernoulliego (4.1):
gdzie do=0, 1, 2, …, N. .
Prawo dystrybucji dwumianowej H.równy liczbie sukcesu n. Testy Bernoulliego, z prawdopodobieństwem sukcesu r..
Dyskretna wartość losowa ma dystrybucję dwumianową (lub dystrybuowaną zgodnie z prawem dwumianowym), jeśli jego możliwe wartości są 0, 1, 2, ... n.i odpowiednie prawdopodobieństwa są obliczane według wzoru (7.1).
Dystrybucja dwumianowa zależy od dwóch parametry r. i n..
Szereg dystrybucji zmiennej losowej, rozpowszechniane zgodnie z prawem dwumianowym, ma formularz:
| H. | … | k. | … | n. | ||
| R. | | … | … | |
Przykład 7.1 . Istnieją trzy niezależne strzały docelowe. Prawdopodobieństwo wprowadzenia każdego strzału wynosi 0,4. Wartość losowa H. - liczba trafień w celu. Zbuduj jej liczbę dystrybucji.
Decyzja. Możliwe wartości zmiennej losowej H. są h. 1 =0; h. 2 =1; h. 3 =2; h. 4 \u003d 3. Znajdujemy odpowiednie prawdopodobieństwa przy użyciu formuły Bernoulli. Łatwo jest pokazać, że użycie tego wzoru jest całkiem uzasadnione. Należy pamiętać, że prawdopodobieństwo nie wprowadzania docelowego na jednym strzaniu będzie 1-0,4 \u003d 0,6. Otrzymać

Wiele dystrybucji jest następujące:
| H. | ||||
| R. | 0,216 | 0,432 | 0,288 | 0,064 |
Łatwo jest sprawdzić, czy suma wszystkich prawdopodobieństw jest równa 1. sama losowa H. Dystrybuowane przez prawo binomianowe. ■.
Znajdujemy oczekiwania matematyczne i dyspersję zmiennej losowej rozpowszechnionej zgodnie z prawem dwumianowym.
Podczas rozwiązywania przykładu 6.5 pokazano, że matematyczne oczekiwanie liczby wydarzeń występów ALE w n. Niezależne testy, jeśli prawdopodobieństwo wyglądu ALE W każdym teście jest stały i równy r.dobrze n.· r.
W tym przykładzie zmienna losowa, dystrybuowana zgodnie z prawem dwumianowym. Dlatego roztwór z przykładu 6.5 jest zasadniczo dowodem następującego twierdzenia.
Twierdzenie 7.1. Matematyczne oczekiwanie dyskretnej zmiennej dystrybuowanej zgodnie z prawem dwumianowym jest równe produktowi liczby testów prawdopodobieństwa prawdopodobieństwa "sukcesu", tj. M.(H.)= N.· r.
Twierdzenie 7.2.Dyspersja dyskretnej zmiennej losowej, rozpowszechniana zgodnie z prawem dwumianowym, jest równa produktowi liczby testów prawdopodobieństwa prawdopodobieństwa prawdopodobieństwa "sukcesu" i prawdopodobieństwa "porażki", tj. RE.(H.)= NPQ.
Asymetria i nadmiar zmiennej losowej, rozproszone zgodnie z prawem dwumianowym, są określane przez wzory
Formuły te można uzyskać przy użyciu koncepcji początkowej i centralnej chwil.
Prawo dwumianowe leży u podstaw wielu rzeczywistych sytuacji. Dla dużych wartości n. Dystrybucja dwumianowa może być przybliżona przez inne dystrybucje, w szczególności za pomocą dystrybucji Poissona.
Dystrybucja Poissona
Niech będzie N.testy Bernoulli, z liczbą testów n. Wystarczająco duży. Wcześniej pokazano, że w tym przypadku (jeśli bardziej prawdopodobne r. Wydarzenia ALE bardzo mały) znaleźć prawdopodobieństwo, że wydarzenie ALE pojawić się t. Raz w testach można użyć formuły Poissona (4.9). Jeśli wartość losowa H. oznacza liczbę zdarzeń ALE w n.testy Bernoulli, prawdopodobieństwo H. Weź wartość k. można obliczyć o wzorze
 , (7.2)
, (7.2)
gdzie λ = nr..
Prawo dystrybucji Poissonanazywany rozkładem dyskretnej zmiennej losowej H.Dla których możliwe wartości są całe numery nie ujemne i prawdopodobieństwa r t. Wartości te znajdują się wzorem (7.2).
Wartość λ = nr.nazywa parametrdystrybucja Poissona.
Zmienna losowa dystrybuowana przez prawo Poissona może wziąć nieskończony zestaw wartości. Jeśli chodzi o prawdopodobieństwo rozkładu r. Wygląd zdarzenia w każdym badaniu jest mały, dystrybucja ta jest czasami nazywana prawem rzadkiej fenomenę.
Wiele dystrybucji zmiennej losowej dystrybuowanej przez prawo Poissona ma formularz
| H. | … | t. | … | ||||
| R. | … | … |
Nie jest trudno upewnić się, że kwota prawdopodobieństwa drugiego ciągu jest 1. W tym celu, konieczne jest, aby pamiętać, że funkcja można rozłożyć w wiersz makrolore, który zbiega się dla każdego h.. W tym przypadku mamy
 . (7.3)
. (7.3)
Jak wspomniano, prawo Poissona w pewnych przypadkach ograniczających zastępuje prawo dwumianowe. Jako przykład możesz przynieść losową kwotę H., których wartości są równe liczbie awarii przez pewien okres czasu z wielokrotnym użyciem urządzenia technicznego. Zakłada się, że jest to urządzenie o wysokiej niezawodności, tj. Prawdopodobieństwo awarii w jednej aplikacji jest bardzo małe.
Oprócz takich marginesów, w praktyce istnieją zmienne losowe rozpowszechniane pod prawem Poissona, które nie są związane z dystrybucją dwumianową. Na przykład dystrybucja Poissona jest często używana, gdy radzą sobie z liczbą zdarzeń, które pojawiają się w momencie czasu (liczba połączeń do wymiany telefonicznej w ciągu godziny, liczba samochodów przybyła do mycia samochodu w ciągu dnia, Liczba przystanków maszyn tygodniowych itp.). Wszystkie te wydarzenia powinny tworzyć, tak zwany przepływ wydarzeń, który jest jedną z podstawowych koncepcji teorii konserwacji masowej. Parametr λ charakteryzuje średnią intensywność przepływu zdarzeń.
Przykład 7.2 . Wydział ma 500 uczniów. Jakie jest prawdopodobieństwo, że 1 września jest urodziny dla trzech studentów tego wydziału?
Decyzja . Od liczby studentów n.\u003d 500 jest wystarczająco duży i r. - Prawdopodobieństwo pierwszego września rodzi się do każdego z uczniów równych, tj. Wystarczająco mała, możemy założyć, że losowa wartość H. - liczba uczniów urodzonych przede wszystkim września jest dystrybuowana pod prawem Poissona z parametrem λ = np.\u003d \u003d 1,36986. Następnie, według formuły (7.2)
Twierdzenie 7.3.Niech losowa wartość H. Dystrybuowane przez prawo poissona. Następnie jego matematyczne oczekiwania i dyspersja są równe wzajemnie i równe wartości parametru λ . M.(X.) = RE.(X.) = λ = np..
Dowód. Określając oczekiwanie matematyczne, stosując formułę (7.3) i szereg dystrybucji zmiennej losowej dystrybuowanej przez prawo Poissona, otrzymujemy
Przed znalezieniem dyspersji znajdziemy matematyczne oczekiwania kwadratowego rozważanego zmiennej losowej. Otrzymać

Stąd, z definicji dyspersji, otrzymujemy
Twierdzenie jest udowodnione.
Stosując koncepcje początkowego i centralnego momentów, można pokazać, że dla zmiennej losowej, rozproszone zgodnie z prawem Poissona, współczynniki asymetrii i ekscesów są określane przez wzory
Nie trudno to zrozumieć, ponieważ w treści semantycznej parametru λ = np. Jest on pozytywny, a następnie asymetria i wymiana są zawsze pozytywnie asymetria i wymiana w zmiennej losowej.
