За даними вибірки знайти емпіричну функцію. Емпірична функція розподілу
Вибіркова середня.
Нехай для вивчення генеральної сукупності щодо кількісної ознаки Х витягнута вибірка обсягу n.
Вибіркової середньої називають середнє арифметичне значення ознаки вибіркової сукупності.
![]()
Вибіркова дисперсія.
Для того, щоб спостерігати розсіювання кількісної ознаки значень вибірки навколо свого середнього значення, вводять зведену характерістіку- вибіркову дисперсію.
Вибіркової дисперсією називають середнє арифметичне квадратів відхилення спостережуваних значень ознаки від їх середнього значення.
Якщо всі значення ознаки вибірки різні, то

Виправлена \u200b\u200bдисперсія.
Вибіркова дисперсія є зміщеною оцінкою генеральної дисперсії, тобто математичне очікування вибіркової дисперсії не дорівнює оцінюваної генеральної дисперсії, а так само
![]()
Для виправлення вибіркової дисперсії досить помножити її на дріб
Вибірковий коефіцієнт кореляціїзнаходиться за формулою

де - вибіркові середні квадратичні відхилення величин і.
Вибірковий коефіцієнт кореляції показує тісноту лінійного зв'язку між і: чим ближче до одиниці, тим сильніше лінійного зв'язку між і.
23. Полігоном частот називають ламану лінію, відрізки якої з'єднують точки. Для побудови полігону частот на осі абсцис відкладають варіанти, а на осі ординат - відповідні їм частоти і з'єднують точки відрізками прямих.
Полігон відносних частот будується аналогічно, за винятком того, що на осі ординат відкладаються відносні частоти.
Гістограмою частот називають ступінчасту фігуру, що складається з прямокутників, підставами якої служать часткові інтервали довжиною h, а висоти дорівнюють відношенню. Для побудови гістограми частот на осі абсцис відкладають часткові інтервали, а над ними проводять відрізки, паралельні осі абсцис на відстані (висоті). Площа i-го прямокутника дорівнює - сумі частот варіант i-о інтервалу, тому площа гістограми частот дорівнює сумі всіх частот, тобто обсягом вибірки.


Емпірична функція розподілу
де n x - число вибіркових значень, менших x; n - обсяг вибірки.
22Определім основні поняття математичної статистики
. Основні поняття математичної статистики. Генеральна сукупність і вибірка. Варіаційний ряд, статистичний ряд. Групувати вибірка. Групувати статистичний ряд. Полігон частот. Вибіркова функція розподілу і гістограма.
Генеральна сукупність- все безліч наявних об'єктів.
вибірка - набір об'єктів, випадково відібраних з генеральної сукупності.
Послідовність варіант, записаних в порядку зростання, називають варіаційнимпоруч, а перелік варіант і відповідних їм частот або відносних частот - дива-стіческій поруч: Чайно відібраних з генеральної сукупності.
полігономчастот називають ламану лінію, відрізки якої з'єднують точки.
гістограмою частот називають ступінчасту фігуру, що складається з прямокутників, підставами якої служать часткові інтервали довжиною h, а висоти дорівнюють відношенню.
Вибіркової (емпіричної) функцією розподілу називають функцію F *(x), Що визначає для кожного значення х відносну частоту події X< x.
Якщо досліджується деякий безперервний ознака, то варіаційний ряд може складатися з дуже великої кількості чисел. В цьому випадку зручніше використовувати групувати вибірку. Для її отримання інтервал, в якому укладені всі спостережувані значення ознаки, розбивають на декілька рівних часткових інтервалів довжиною h, А потім знаходять для кожного часткового інтервалу n i - суму частот варіант, які потрапили в i-й інтервал.
20. Під законом великих чисел не слід розуміти якийсь один загальний закон, пов'язаний з великими числами. Закон великих чисел - це узагальнена назва декількох теорем, з яких випливає, що при необмеженому збільшенні числа випробувань середні величини прагнуть до деяких постійним.
До них відносяться теореми Чебишева і Бернуллі. Теорема Чебишева є найбільш загальним законом великих чисел.
В основі доведення теорем, об'єднаних терміном "закон великих чисел", лежить нерівність Чебишева, за яким встановлюється ймовірність відхилення від її математичного очікування:
![]()
19Распределеніе Пірсона (хі - квадрат) - розподіл випадкової величини
де випадкові величини X 1, X 2, ..., X n незалежні і мають один і той же розподіл N(0,1). При цьому число доданків, тобто n, Називається «числом ступенів свободи» розподілу хі - квадрат.
Розподіл хі-квадрат використовують при оцінюванні дисперсії (за допомогою довірчого інтервалу), при перевірці гіпотез згоди, однорідності, незалежності,
розподіл t Стьюдента - це розподіл випадкової величини
де випадкові величини U і X незалежні, U має розподіл стандартний нормальний розподіл N(0,1), а X - розподіл хі - квадрат з n ступенями свободи. При цьому n називається «числом ступенів свободи» розподілу Стьюдента.
Його застосовують при оцінюванні математичного очікування, прогнозного значення і інших характеристик за допомогою довірчих інтервалів, по перевірці гіпотез про значення математичних очікувань, коефіцієнтів регресійної залежності,
Розподіл Фішера - це розподіл випадкової величини
Розподіл Фішера використовують при перевірці гіпотез про адекватність моделі в регресійному аналізі, про рівність дисперсій і в інших завданнях прикладної статистики
18лінійна регресія є статистичним інструментом, використовуваним для прогнозування майбутніх цін виходячи з минулих даних, і зазвичай застосовується, щоб визначити, коли ціни є перегрітими. Використовується метод найменшого квадрата для побудови «найбільш підходящою» прямій лінії через ряд точок цінових значень. Ціновими точками, що використовуються в якості вхідних даних, може бути будь-яка з наступних значень: відкриття, закриття, максимум, мінімум,
17. двовимірної випадкової величиною називають упорядкований набір з двох випадкових величин або.
Прімер.Подбрасиваются два гральних кубика. - число очок, що випали на першому і другому кубиках відповідно
Універсальний спосіб завдання закону розподілу двовимірної випадкової величини - це функція розподілу.
15.м.О Дискретні випадкові величини
властивості:
1) M(C) = C, C - постійна;
2) M(CX) = CM(X);
3) M(X 1 + X 2) = M(X 1) + M(X 2), Де X 1, X 2 - незалежні випадкові величини;
4) M(X 1 X 2) = M(X 1)M(X 2).
Математичне сподівання суми випадкових величин дорівнює сумі їх математичних очікувань, тобто
Математичне сподівання різниці випадкових величин дорівнює різниці їх математичних очікувань, тобто
Математичне сподівання добутку випадкових величин дорівнює добутку їх математичних очікувань, тобто
Якщо всі значення випадкової величини збільшити (зменшити) на одне і теж число С, то її математичне очікування збільшиться (зменшиться) на це ж число
14. показовий(експонентний) закон розподілу X має показовий (експонентний) закон розподілу з параметром λ\u003e 0, якщо її щільність ймовірності має вигляд:
![]()
Математичне очікування: .
Дисперсія:.
Показовий закон розподілу грає велику роль в теорії масового обслуговування і теорії надійності.
13. Нормальний закон розподілу характеризується частотою відмов a (t) або щільністю ймовірності відмов f (t) виду:
 , (5.36)
, (5.36)
де σ- середньоквадратичне відхилення СВ x;
m x - математичне очікування СВ x. Цей параметр часто називають центром розсіювання або найбільш імовірним значенням СВ Х.
x- випадкова величина, за яку можна прийняти час, значення струму, значення електричної напруги та інших аргументів.
Нормальний закон - це двухпараметрический закон, для запису якого потрібно знати m x і σ.
Нормальний розподіл (розподіл Гауса) використовується при оцінці надійності виробів, на які впливає ряд випадкових факторів, кожен з яких має незначний вплив на результуючий ефект
12. Рівномірний закон розподілу. Безперервна випадкова величина X має рівномірний закон розподілу на відрізку [ a, b], Якщо її щільність ймовірності постійна на цьому відрізку і дорівнює нулю поза ним, тобто

Позначення:.
Математичне очікування: .
Дисперсія:.
Випадкова величина Х, Розподілена по рівномірному закону на відрізку називається випадковим числом від 0 до 1. Вона служить вихідним матеріалом для отримання випадкових величин з будь-яким законом розподілу. Рівномірний закон розподілу використовується при аналізі помилок округлення при проведенні числових розрахунків, в ряді завдання масового обслуговування, при статистичному моделюванні спостережень, підпорядкованих заданому розподілу.
11. Визначення. щільністю розподілу ймовірностей неперервної випадкової величини Х називається функція f (x) - перша похідна від функції розподілу F (x).
Щільність розподілу також називають диференціальної функцією. Для опису випадкової величини щільність розподілу є неприйнятною.
Сенс щільності розподілу полягає в тому, що вона показує як часто з'являється випадкова величина Х в деякій околиці точки х при повторенні дослідів.
Після введення функцій розподілу і щільності розподілу можна дати наступне визначення неперервної випадкової величини.
10. Щільність ймовірності, щільність розподілу ймовірностей випадкової величини x, - функція p (x) така, що 
і при будь-яких a< b вероятность события a < x < b равна
.
Якщо p (x) неперервна, то при досить малих Δx ймовірність нерівності x< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
і, якщо F (x) диференційована, то ![]()
Лекція 13. Поняття про статистичні оцінках випадкових величин
Нехай відомо статистичний розподіл частот кількісної ознаки X. Позначимо через число спостережень, при яких спостерігалося значення ознаки, менше x і через n - загальне число спостережень. Очевидно, відносна частота події X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Емпіричної функцією розподілу (Функцією розподілу вибірки) називають функцію, що визначає для кожного значення x відносну частоту події X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
На відміну від емпіричної функції розподілу вибірки, функцію розподілу генеральної сукупності називають теоретичної функцією розподілу.Різниця між цими функціями полягає в тому, що теоретична функціяопределяет ймовірністьподії X< x, тогда как эмпирическая – відносну частотуцього ж події.
При зростанні n відносна частота події X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Властивості емпіричної функції розподілу:
1) Значення емпіричної функції належать відрізку
2) - неубутна функція
3) Якщо - найменша варіанта, то \u003d 0 при, якщо - найбільша варіанта, то \u003d 1 при.
Емпірична функція розподілу вибірки служить для оцінки теоретичної функції розподілу генеральної сукупності.
приклад. Побудуємо емпіричну функцію по розподілу вибірки:
| варіанти | |||
| частоти |
Знайдемо обсяг вибірки: 12 + 18 + 30 \u003d 60. Найменша варіанта дорівнює 2, тому \u003d 0 при x £ 2. Значення x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x> 10. таким чином, шукана емпірична функція має вигляд:
Найважливіші властивості статистичних оцінок
Нехай потрібно вивчити деякий кількісний ознака генеральної сукупності. Припустимо, що з теоретичних міркувань вдалося встановити, яке саме розподіл має ознака і необхідно оцінити параметри, якими воно визначається. Наприклад, якщо досліджуваний ознака розподілений в генеральної сукупності нормально, то потрібно оцінити математичне сподівання і середнє квадратичне відхилення; якщо ознака має розподіл Пуассона - то необхідно оцінити параметр l.
Зазвичай є лише дані вибірки, наприклад значення кількісної ознаки, отримані в результаті n незалежних спостережень. Розглядаючи як незалежні випадкові величини можна сказати, що знайти статистичну оцінку невідомого параметра теоретичного розподілу - значить знайти функцію від спостережуваних випадкових величин, яка дає наближене значення оцінюваного параметра. Наприклад, для оцінки математичного очікування нормального розподілу роль функції виконує середнє арифметичне
Для того щоб статистичні оцінки давали коректні наближення оцінюваних параметрів, вони повинні задовольняти деяким вимогам, серед яких найважливішими є вимоги незсуненості і спроможності оцінки.
Нехай - статистична оцінка невідомого параметра теоретичного розподілу. Нехай за вибіркою обсягу n знайдена оцінка. Повторимо досвід, тобто винесемо з генеральної сукупності іншу вибірку того ж обсягу і за її даними отримаємо іншу оцінку. Повторюючи досвід багаторазово, отримаємо різні числа. Оцінку можна розглядати як випадкову величину, а числа - як її можливі значення.
Якщо оцінка дає наближене значення з надлишком, Тобто кожне число більше істинного значення то, як наслідок, математичне очікування (середнє значення) випадкової величини більше, ніж:. Аналогічно, якщо дає оцінку з недоліком, То.
Таким чином, використання статистичної оцінки, математичне очікування якої не дорівнює оцінюваному параметру, призвело б до систематичних (одного знака) помилок. Якщо, навпаки,, то це гарантує від систематичних помилок.
незміщеної називають статистичну оцінку, математичне очікування якої дорівнює оцінюваному параметру при будь-якому обсязі вибірки.
зміщеною називають оцінку, що не задовольняє цій умові.
Незміщеність оцінки ще не гарантує отримання хорошого наближення для оцінюваного параметра, так як можливі значення можуть бути сильно розпорошені навколо свого середнього значення, тобто дисперсія може бути значною. В цьому випадку знайдена за даними однієї вибірки оцінка, наприклад, може виявитися значно віддаленій від середнього значення, а значить, і від самого оцінюваного параметра.
ефективною називають статистичну оцінку, яка, при заданому обсязі вибірки n, має найменшу можливу дисперсію .
При розгляді вибірок великого обсягу до статистичних оцінок ставиться вимога спроможності .
заможної називається статистична оцінка, яка при n® ¥ прагне за ймовірністю до оцінюваного параметру. Наприклад, якщо дисперсія несмещенной оцінки при n® ¥ прагне до нуля, то така оцінка виявляється і заможної.
Визначення емпіричної функції розподілу
Нехай $ X $ - випадкова величина. $ F (x) $ - функція розподілу даної випадкової величини. Будемо проводити в одних і тих же незалежних один від одного умов $ n $ дослідів над даної випадкової величиною. При цьому отримаємо послідовність значень $ x_1, \\ x_2 \\ $, ..., $ \\ x_n $, яка і називається вибіркою.
визначення 1
Кожне значення $ x_i $ ($ i \u003d 1,2 \\ $, ..., $ \\ n $) називається варіант.
Однією з оцінок теоретичної функції розподілу є емпірична функція розподілу.
визначення 3
Емпіричної функцією розподілу $ F_n (x) $ називається функція, яка визначає для кожного значення $ x $ відносну частоту події $ X \\
де $ n_x $ - число варіант, менших $ x $, $ n $ - обсяг вибірки.
Відмінність емпіричної функції від теоретичної полягає тому, що теоретична функція визначає ймовірність події $ X
Властивості емпіричної функції розподілу
Розглянемо тепер кілька основних властивостей функції розподілу.
Область значень функції $ F_n \\ left (x \\ right) $ - відрізок $$.
$ F_n \\ left (x \\ right) $ неубутна функція.
$ F_n \\ left (x \\ right) $ безперервна зліва функція.
$ F_n \\ left (x \\ right) $ кусочно-постійна функція і зростає тільки в точках значень випадкової величини $ X $
Нехай $ X_1 $ - найменша, а $ X_n $ - найбільша варіанта. Тоді $ F_n \\ left (x \\ right) \u003d 0 $ при $ (x \\ le X) _1 $ і $ F_n \\ left (x \\ right) \u003d 1 $ при $ x \\ ge X_n $.
Введемо теорему, яка пов'язує між собою теоретичну і емпіричну функції.
теорема 1
Нехай $ F_n \\ left (x \\ right) $ - емпірична функція розподілу, а $ F \\ left (x \\ right) $ - теоретична функція розподілу генеральної вибірки. Тоді виконується рівність:
\\ [(\\ Mathop (lim) _ (n \\ to \\ infty) (| F) _n \\ left (x \\ right) -F \\ left (x \\ right) | \u003d 0 \\) \\]
Приклади завдань на знаходження емпіричної функції розподілу
приклад 1
Нехай розподіл вибірки має наступні дані, записані за допомогою таблиці:
Малюнок 1.
Знайти обсяг вибірки, скласти емпіричну функцію розподілу і побудувати її графік.
Обсяг вибірки: $ n \u003d 5 + 10 + 15 + 20 \u003d 50 $.
По властивості 5, маємо, що при $ x \\ le 1 $ $ F_n \\ left (x \\ right) \u003d 0 $, а при $ x\u003e 4 $ $ F_n \\ left (x \\ right) \u003d 1 $.
Значення $ x
Значення $ x
Значення $ x
Таким чином, отримуємо:

Малюнок 2.

Малюнок 3.
приклад 2
З міст центральної частини Росії випадковим чином вибрано 20 міст, для яких отримані наступні дані по вартості проїзду в громадському транспорті: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14, 15, 13 , 13, 12, 12, 15, 14, 14.
Скласти емпіричну функцію розподілу даної вибірки і побудувати її графік.
Запишемо значення вибірки в порядку зростання і порахуємо частоту кожного значення. Отримуємо наступну таблицю:
Малюнок 4.
Обсяг вибірки: $ n \u003d 20 $.
По властивості 5, маємо, що при $ x \\ le 12 $ $ F_n \\ left (x \\ right) \u003d 0 $, а при $ x\u003e 15 $ $ F_n \\ left (x \\ right) \u003d 1 $.
Значення $ x
Значення $ x
Значення $ x
Таким чином, отримуємо:

Малюнок 5.
Побудуємо графік емпіричного розподілу:

Малюнок 6.
Оригінальність: $ 92,12 \\% $.
Дізнайтеся, що таке емпірична формула. У хімії ЕФ - це найпростіший спосіб опису з'єднання - по суті це список елементів, що утворюють з'єднання з урахуванням їхнього процентного вмісту. Потрібно звернути увагу, що ця проста формула не описує порядок атомів в з'єднанні, вона просто вказує, з яких елементів воно складається. For example:
- З'єднання, що складається з 40,92% вуглецю; 4,58% водню і 54,5% кисню, матиме емпіричну формулу C 3 H 4 O 3 (приклад того, як знайти ЕФ цього з'єднання буде розглянуто у другій частині).
Запам'ятайте термін "процентний склад". "Відсотковим складом" називається процентний вміст кожного окремого атома в усьому розглянутому з'єднанні. Щоб знайти емпіричну формулу сполуки, необхідно знати процентний склад з'єднання. Якщо ви знаходите емпіричну формулу в якості домашнього завдання, то відсотки, швидше за все, будуть дані.
- Щоб знайти процентний склад хімічної сполуки в лабораторії, його піддають деяким фізичним експериментів, а потім - кількісного аналізу. Якщо ви не перебуваєте в лабораторії, вам не потрібно робити ці експерименти.
Майте на увазі, що вам доведеться мати справу з грам-атомами. Грам-атом - це певна кількість речовини, маса якого дорівнює його атомній масі. Щоб знайти грам-атом, потрібно скористатися таким рівнянням: Процентний вміст елемента в з'єднанні ділиться на атомну масу елемента.
- Припустимо, наприклад, що у нас є з'єднання, що містить 40,92% вуглецю. Атомна маса вуглецю дорівнює 12, тому наше рівняння матиме 40,92 / 12 \u003d 3,41.
Знайте, як знаходити атомне співвідношення. Працюючи з з'єднанням, у вас буде виходити більше одного грам-атома. Після знаходження всіх грам-атомів вашого з'єднання, подивіться на них. Для того, щоб знайти атомне співвідношення, вам потрібно буде вибрати найменше значення грам-атома, які ви вирахували. Потім потрібно буде розділити всі грам-атоми на найменший грам-атом. наприклад:
- Припустимо ви працюєте з сполукою, що містить три грам-атома: 1,5; 2 і 2,5. Найменше з цих чисел - 1,5. Тому, щоб визначити співвідношення атомів, ви повинні розділити всі числа на 1,5 і поставити між ними знак відносини : .
- 1,5 / 1,5 \u003d 1. 2 / 1,5 \u003d 1,33. 2,5 / 1,5 \u003d 1,66. Отже, співвідношення атомів одно 1: 1,33: 1,66 .
Розберіться, як переводити значення відносин атомів в цілі числа. Записуючи емпіричну формулу, ви повинні використовувати цілі числа. Це означає, що ви не можете використовувати числа начебто 1,33. Після того, як ви знайдете відношення атомів, вам потрібно перевести дробові числа (на кшталт 1,33) в цілі (наприклад, 3). Для цього вам потрібно знайти ціле число, помноживши на яку кожна число атомного співвідношення, ви отримаєте цілі числа. наприклад:
- Спробуйте 2. Помножте числа атомного співвідношення (1, 1,33 і 1,66) на 2. Ви отримаєте 2, 2,66 та 3,32. Це не цілі числа, тому 2 не підходить.
- Спробуйте 3. Якщо ви помножите 1, 1,33 і 1,66 на 3, у вас вийде 3, 4 і 5 відповідно. Отже, атомне співвідношення цілих чисел має вигляд 3: 4: 5 .
Як відомо, закон розподілу випадкової величини можна задавати різними способами. Дискретну випадкову величину можна задати за допомогою ряду розподілу або інтегральної функції, а безперервну випадкову величину - за допомогою або інтегральної, або диференціальної функції. Розглянемо вибіркові аналоги цих двох функцій.
Нехай є вибіркова сукупність значень деякої випадкової величини обсягу  і кожному варіанту з цієї сукупності поставлена \u200b\u200bу відповідність його частость. Нехай далі,
і кожному варіанту з цієї сукупності поставлена \u200b\u200bу відповідність його частость. Нехай далі,  - деяке дійсне число, а
- деяке дійсне число, а  - число вибіркових значень випадкової величини
- число вибіркових значень випадкової величини  , менших
, менших  .Тоді число
.Тоді число  є частостей спостережуваних у вибірці значень величини X, менших
є частостей спостережуваних у вибірці значень величини X, менших  ,
тобто частостей появи події
,
тобто частостей появи події 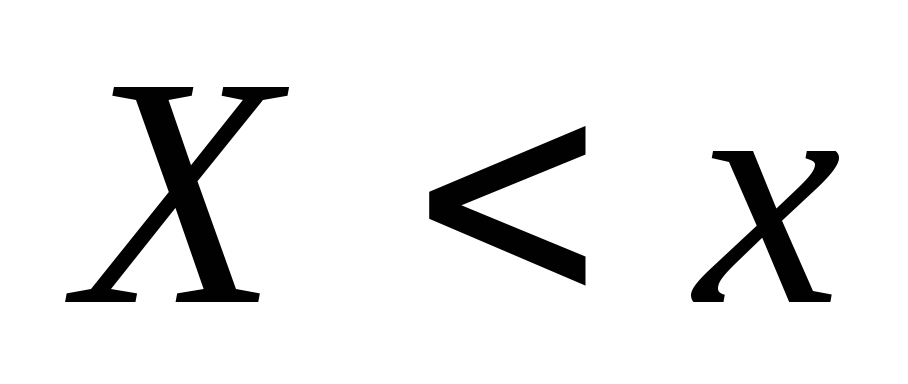 . При зміні x в загальному випадку буде змінюватися і величина
. При зміні x в загальному випадку буде змінюватися і величина  . Це означає, що відносна частота
. Це означає, що відносна частота  є функцією аргументу
є функцією аргументу  . А так як ця функція знаходиться за вибірковими даними, отриманим в результаті дослідів, то її називають вибіркової або емпіричної.
. А так як ця функція знаходиться за вибірковими даними, отриманим в результаті дослідів, то її називають вибіркової або емпіричної.
Визначення 10.15. Емпіричної функцією розподілу (Функцією розподілу вибірки) називають функцію  , Визначає для кожного значення x відносну частоту події
, Визначає для кожного значення x відносну частоту події  .
.
 (10.19)
(10.19)
На відміну від емпіричної функції розподілу вибірки функцію розподілу F(x) Генеральної сукупності називають теоретичної функцією розподілу. Різниця між ними полягає в тому, що теоретична функція F(x)
визначає ймовірність події  , А емпірична - відносну частоту цього ж події. З теореми Бернуллі слід
, А емпірична - відносну частоту цього ж події. З теореми Бернуллі слід
 ,
,
 (10.20)
(10.20)
тобто при великих  ймовірність
ймовірність  і відносна частота події
і відносна частота події  , Тобто
, Тобто  мало відрізняються одне від іншого. Вже звідси випливає доцільність використання емпіричної функції розподілу вибірки для наближеного представлення теоретичної (інтегральної) функції розподілу генеральної сукупності.
мало відрізняються одне від іншого. Вже звідси випливає доцільність використання емпіричної функції розподілу вибірки для наближеного представлення теоретичної (інтегральної) функції розподілу генеральної сукупності.
функція  і
і  мають однакові властивості. Це випливає з визначення функції.
мають однакові властивості. Це випливає з визначення функції. 
властивості  :
:

Приклад 10.4. Побудувати емпіричну функцію по даному розподілу вибірки:
|
варіанти | |||
|
частоти |


Рішення: Знайдемо обсяг вибірки n=
12 + 18 + 30 \u003d 60. найменша варіанта  , Отже,
, Отже,  при
при  . значення
. значення  , а саме
, а саме  спостерігалося 12 разів, отже:
спостерігалося 12 разів, отже:
 =
= при
при  .
.
значення x<
10, а саме  і
і  спостерігалися 12 + 18 \u003d 30 разів, отже,
спостерігалися 12 + 18 \u003d 30 разів, отже,  =
=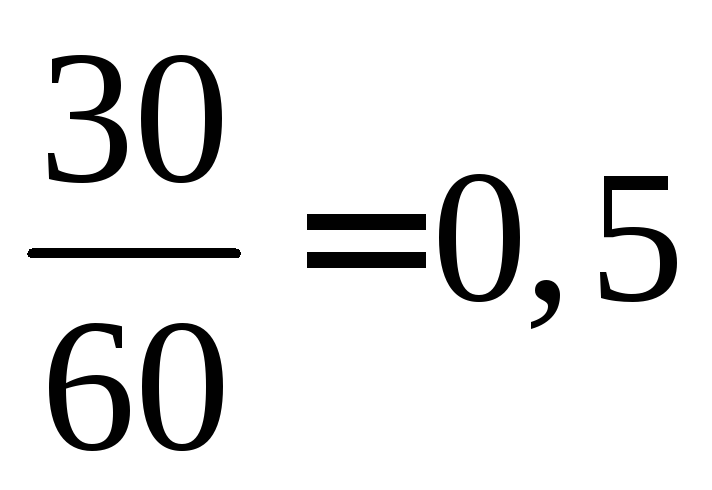 при
при  . при
. при 
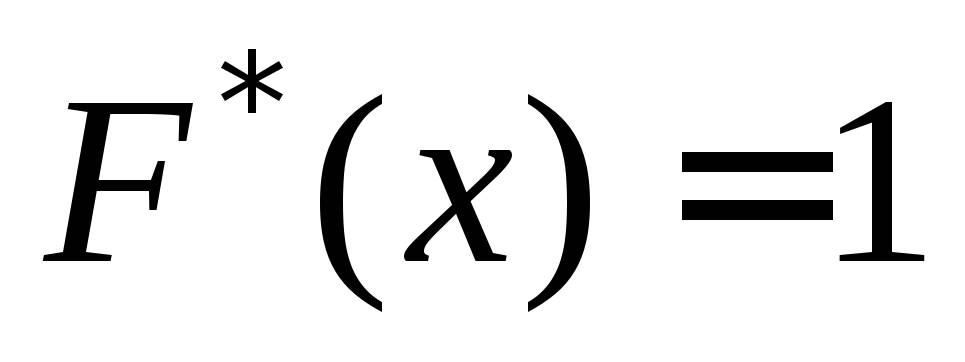 .
.
Шукана емпірична функція розподілу:
 =
=
Графік  представлений на рис. 10.2
представлений на рис. 10.2
Р  ис. 10.2
ис. 10.2
Контрольні питання
1. Які основні завдання вирішує математична статистика? 2. Генеральна і вибіркова сукупність? 3. Дайте визначення обсягу вибірки. 4. Які вибірки називаються репрезентативними? 5. Помилки репрезентативності. 6. Основні способи освіти вибірки. 7. Поняття частоти, відносної частоти. 8. Поняття статистичного ряду. 9. Запишіть формулу Стерджеса. 10. Сформулюйте поняття розмаху вибірки, медіани і моди. 11. Полігон частот, гістограма. 12. Поняття точкової оцінки вибіркової сукупності. 13. Зміщена і несмещенная точкова оцінка. 14. Сформулюйте поняття вибіркової середньої. 15. Сформулюйте поняття вибіркової дисперсії. 16. Сформулюйте поняття вибіркового середньоквадратичного відхилення. 17. Сформулюйте поняття вибіркового коефіцієнта варіації. 18. Сформулюйте поняття вибіркової середньої геометричної.
